Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
None
-
Lustre 2.10.7
-
None
-
RHEL 7.2.1511, lustre version 2.10.7-1
-
3
-
9223372036854775807
Description
MDS filesystem is full, and we cannot free space on it. It will crash (kernel panic) when trying to delete files.
Apr 13 16:01:50 emds1 kernel: LDISKFS-fs (md0): mounted filesystem with ordered data mode. Opts: user_xattr,errors=remount-ro,no_mbcache,nodelalloc Apr 13 16:01:50 emds1 kernel: LustreError: 11368:0:(osd_handler.c:7131:osd_mount()) echo-MDT0000-osd: failed to set lma on /dev/md0 root inode Apr 13 16:01:50 emds1 kernel: LustreError: 11368:0:(obd_config.c:558:class_setup()) setup echo-MDT0000-osd failed (-30) Apr 13 16:01:50 emds1 kernel: LustreError: 11368:0:(obd_mount.c:203:lustre_start_simple()) echo-MDT0000-osd setup error -30 Apr 13 16:01:50 emds1 kernel: LustreError: 11368:0:(obd_mount_server.c:1848:server_fill_super()) Unable to start osd on /dev/md0: -30 Apr 13 16:01:50 emds1 kernel: LustreError: 11368:0:(obd_mount.c:1582:lustre_fill_super()) Unable to mount (-30) Apr 13 16:02:01 emds1 kernel: LDISKFS-fs (md0): mounted filesystem with ordered data mode. Opts: user_xattr,errors=remount-ro,no_mbcache,nodelalloc Apr 13 16:02:01 emds1 kernel: Lustre: MGS: Connection restored to 8f792be4-fada-1d75-0dbd-ec8601cdce7f (at 0@lo) Apr 13 16:02:01 emds1 kernel: LustreError: 11438:0:(genops.c:478:class_register_device()) echo-OST0000-osc-MDT0000: already exists, won't add Apr 13 16:02:01 emds1 kernel: LustreError: 11438:0:(obd_config.c:1682:class_config_llog_handler()) MGC10.23.22.104@tcp: cfg command failed: rc = -17 Apr 13 16:02:01 emds1 kernel: Lustre: cmd=cf001 0:echo-OST0000-osc-MDT0000 1:osp 2:echo-MDT0000-mdtlov_UUID Apr 13 16:02:01 emds1 kernel: LustreError: 15c-8: MGC10.23.22.104@tcp: The configuration from log 'echo-MDT0000' failed (-17). This may be the result of communication errors between this node and the MGS, a bad configuration, or other errors. See the syslog for more information. Apr 13 16:02:01 emds1 kernel: LustreError: 11380:0:(obd_mount_server.c:1389:server_start_targets()) failed to start server echo-MDT0000: -17 Apr 13 16:02:01 emds1 kernel: LustreError: 11380:0:(obd_mount_server.c:1882:server_fill_super()) Unable to start targets: -17 Apr 13 16:02:01 emds1 kernel: Lustre: Failing over echo-MDT0000 Apr 13 16:02:07 emds1 kernel: Lustre: 11380:0:(client.c:2116:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1586818921/real 1586818921] req@ffff8d748ab38000 x1663898946110400/t0(0) o251->MGC10.23.22.104@tcp@0@lo:26/25 lens 224/224 e 0 to 1 dl 1586818927 ref 2 fl Rpc:XN/0/ffffffff rc 0/-1 Apr 13 16:02:08 emds1 kernel: Lustre: server umount echo-MDT0000 complete Apr 13 16:02:08 emds1 kernel: LustreError: 11380:0:(obd_mount.c:1582:lustre_fill_super()) Unable to mount (-17)
Attachments
Issue Links
Activity
As for the debugfs stat output, it definitely shows that the "link" xattr is large in at least some cases, and would consume an extra block for each such inode. Also, based on the previous e2fsck issue, it seems that there are a very large number of directories compared to regular files, and each directory will also consume at least one block. Based on LU-13197, the filesystem must have at least 180M directories for only 850M inodes, so only about 5 files per directory (although this doesn't take into account the number of hard links).
The dir_info e2fsck error appears to be the same as LU-13197, which has a patch to fix it. There is a RHEL7 build of e2fsprogs that is known to fix this specific issue:
This e2fsck bug was hit at another site that has a very large number of directories (over 180M directories), which is unusual for most cases, but in the case of your symlink trees there are lots of directories with relatively few directories. The updated e2fsck was confirmed to fix the problem on their filesystem.
I am however able now to delete files without a panic.
I'm going to try and clear space and see if we can get a backup through overnight and then check the logs tomorrow. Looks like another fsck is going to be required...
A couple of debugfs examples:
debugfs -c -R 'stat /ROOT/ARCHIVE/dirvish/filers/vannfs31/20200328/tree/user_data/CRB_RESTORES/IO-82556/CRB/ldev_2d_elements/SCAN/S_ldev_2d_elements_blood_element_squib_large_flat_a_002_s01/2156x1806/s_ldev_2d_elements_blood_element_squib_large_flat_a_002_s01.1117.exr' /dev/md0 debugfs 1.45.2.wc1 (27-May-2019) /dev/md0: catastrophic mode - not reading inode or group bitmaps Inode: 1734097604 Type: regular Mode: 0444 Flags: 0x0 Generation: 294602363 Version: 0x00000025:b9345598 User: 4014 Group: 20 Project: 0 Size: 0 File ACL: 1084109575 Links: 22 Blockcount: 8 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x5e901af0:00000000 -- Fri Apr 10 00:06:24 2020 atime: 0x5e6b3965:00000000 -- Fri Mar 13 00:42:29 2020 mtime: 0x5a21f22f:00000000 -- Fri Dec 1 16:22:07 2017 crtime: 0x5e6b3965:c27fd8ec -- Fri Mar 13 00:42:29 2020 Size of extra inode fields: 32 Extended attributes: trusted.lma (24) = 00 00 00 00 00 00 00 00 68 82 00 00 02 00 00 00 83 ac 01 00 00 00 00 00 lma: fid=[0x200008268:0x1ac83:0x0] compat=0 incompat=0 trusted.lov (56) trusted.link (1916) BLOCKS:
debugfs -c -R 'stat /ROOT/ARCHIVE/dirvish/filers/gungnir-vol/20200404/tree/vol/builds/usd/0.7.0/e2f93f71e4/lib/python/pxr/Pcp/__init__.py' /dev/md0 debugfs 1.45.2.wc1 (27-May-2019) /dev/md0: catastrophic mode - not reading inode or group bitmaps Inode: 820727609 Type: regular Mode: 0644 Flags: 0x0 Generation: 3289393243 Version: 0x00000025:9a66a677 User: 518 Group: 20 Project: 0 Size: 0 File ACL: 0 Links: 6 Blockcount: 0 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x5e95e738:6ca5e29c -- Tue Apr 14 09:39:20 2020 atime: 0x5d63cb50:00000000 -- Mon Aug 26 05:06:40 2019 mtime: 0x579ffa2d:00000000 -- Mon Aug 1 18:41:01 2016 crtime: 0x5d63cb50:820f5640 -- Mon Aug 26 05:06:40 2019 Size of extra inode fields: 32 Extended attributes: trusted.lma (24) = 00 00 00 00 00 00 00 00 f5 16 00 00 02 00 00 00 15 67 01 00 00 00 00 00 lma: fid=[0x2000016f5:0x16715:0x0] compat=0 incompat=0 trusted.lov (56) trusted.link (285) BLOCKS:
Unfortunately:
emds1 /root # e2fsck -fvy -C 0 /dev/md0 e2fsck 1.45.2.wc1 (27-May-2019) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Internal error: couldn't find dir_info for 2391487120. e2fsck: aborted
Very annoyingly we noticed that we didn't have inode stats turned on in collectd. We've corrected this but only as of today unfortunately.
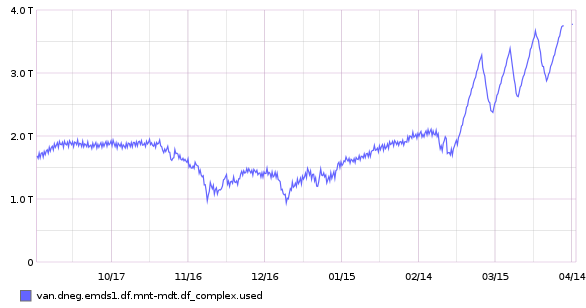
When you have a chance (not urgent) it would be useful to check whether the trend for "df -i" on the MDT (if you track this history) is increasing similarly as shown in df.png. That would at least tell us if the extra usage is new files (it both used space and inodes are growing at about the same rate) or it is extra space usage per file or elsewhere (if space usage is increasing while inode usage is roughly constant).
I'll do that as soon as the fsck completes and before I mount as lustre to try and delete stuff. It's certainly likely that we'll exceed the 450 bytes on almost all the files because we maintain (usually) 2 or 3 weeks of daily hard linked backups for each server so up to roughly 21 hard links per file.
Again though this hasn't changed recently, it's been this way for some time and I'm not sure what would have caused such an incredible linear increase in the numbers of files/size used.
You could also use "debugfs -c -R 'stat <inode_number> [<inode_number> ...]' /dev/md0" to dump the attributes of of a few problematic inodes previously reported by e2fsck, if they haven't already been fixed. That might give us an idea of what went wrong with them.
The other problem to understand/address is what is consuming the space on the MDT. You could check this if you know some files that were backed up recently, and run "debugfs -c -R 'stat /ROOT/path/to/backup/file' /dev/md0" to dump the inode information. The "catastrophic mode" message is not cause for alarm, just the "-c" flag skipping loading of unnecessary filesystem metadata to run faster. This should dump something like:
debugfs 1.45.2.wc1 (27-May-2019) /tmp/testfs-mdt1: catastrophic mode - not reading inode or group bitmaps Inode: 171 Type: regular Mode: 0644 Flags: 0x0 Generation: 225492012 Version: 0x00000005:000099b6 User: 0 Group: 0 Project: 0 Size: 0 File ACL: 3525837 Links: 1 Blockcount: 0 Fragment: Address: 0 Number: 0 Size: 0 ctime: 0x5e8d87f3:00000000 -- Wed Apr 8 02:14:43 2020 atime: 0x5e8d87f3:00000000 -- Wed Apr 8 02:14:43 2020 mtime: 0x5e8d87f3:00000000 -- Wed Apr 8 02:14:43 2020 crtime: 0x5e8d87f3:45e6e870 -- Wed Apr 8 02:14:43 2020 Size of extra inode fields: 32 Extended attributes: trusted.lma (24) = 00 00 00 00 00 00 00 00 42 23 00 00 02 00 00 00 bd 03 00 00 00 00 00 00 lma: fid=[0x200002342:0x3bd:0x0] compat=0 incompat=0 trusted.lov (56) security.selinux (37) = "unconfined_u:object_r:unlabeled_t:s0\000" trusted.link (968) trusted.som (24) = 04 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 BLOCKS:
and of interest is the "File ACL:" line being non-zero (indicating an external xattr block) and the "trusted.link (968)" xattr line showing that it is large (at least larger than can fit into the remaining ~450 bytes of xattr space available in the inode). If that is the case, you might be able to reduce this xattr space usage by removing one of your older backup copies, or some old directory trees that have lots of files with these large xattrs.
Our directory trees are ridiculously deep and overused for structure of data so this doesn't surprise me. I'm still not sure what changed end of Feb though so we're gonna have to watch this carefully.
Checking this morning, backups are still running and seem to be somewhat stable so I'll let a good backup complete then try and take it offline to run a new e2fsck.
After we've had a successful e2fsck, I'd like to upgrade to 2.12.4 but would it be sensible to run an lfsck prior to doing that, or after to get all the updates/bug-fixes?