Details
-
Bug
-
Resolution: Fixed
-
 Minor
Minor
-
Lustre 2.4.0
-
None
-
3
-
5779
Description
Once the "layout swap" support in LU-2017 (http://review.whamcloud.com/4507) is landed, the client will have an API to atomically swap the layout between two files.
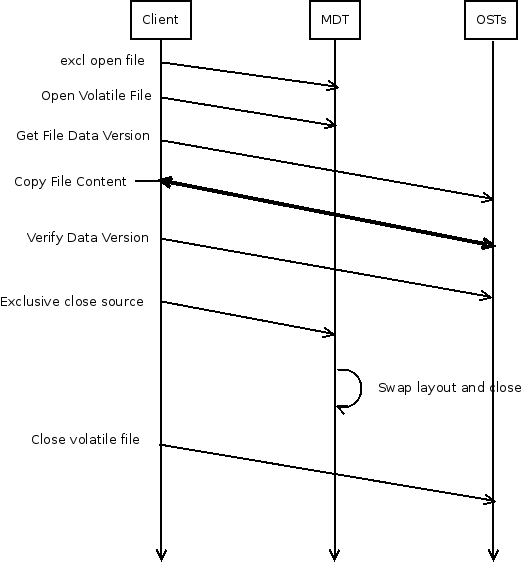
In order for this functionality to be useful for users, the llapi_layout_swap() function needs to be wrapped in some additional code compared to lfs swap_layouts to ensure that the file isn't changing during the copy, and to do the actual copy.
I propose an lfs migrate command that takes the same arguments as lfs setstripe (calling into lfs_setstripe() to create the target file, for simplicity and compatibility, though with some option to make it an open-unlinked file via LU-2441), gets an exclusive lock on the file (group lock or client-side layout lock), and then copies the file contents from the source to the target. By reading the whole source file, this will natually cause any clients with unwritten data to flush their caches when their write-extent locks are cancelled. Once the copy is completed (optionally verifying the data checksum after flushing the client cache?) the llapi_layout_swap() function is called, and the "new" open-unlinked file descriptor layout (which now points to the old objects) is closed, causing those objects to be destroyed. The exclusive lock can be dropped.
If the MDS does not support MDS_SWAP_LAYOUTS then lfs migrate should return an -EOPNOTSUPP error, so that users are aware that atomic layout swap is not available.
The lfs_migrate script should call the lfs migrate command to do the migrate/copy (instead of rsync + mv). but lfs_migrate probably needs to fall back to rsync+mv again. The lfs_migrate script has not previously guaranteed atomic migration, so it should continue to work using rsync+mv as it has in the past if "lfs migrate" returns EOPNOTSUPP, with a comment to the effect that this functionality should be removed after Lustre 2.10 or so.
Attachments
Issue Links
- is related to
-
-

- Resolved
-
