Details
-
Bug
-
Resolution: Fixed
-
 Minor
Minor
-
Lustre 2.4.0
-
None
-
3
-
5779
Description
Once the "layout swap" support in LU-2017 (http://review.whamcloud.com/4507) is landed, the client will have an API to atomically swap the layout between two files.
In order for this functionality to be useful for users, the llapi_layout_swap() function needs to be wrapped in some additional code compared to lfs swap_layouts to ensure that the file isn't changing during the copy, and to do the actual copy.
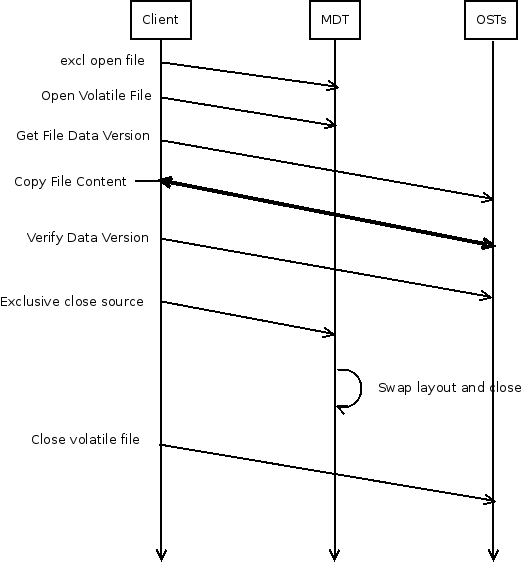
I propose an lfs migrate command that takes the same arguments as lfs setstripe (calling into lfs_setstripe() to create the target file, for simplicity and compatibility, though with some option to make it an open-unlinked file via LU-2441), gets an exclusive lock on the file (group lock or client-side layout lock), and then copies the file contents from the source to the target. By reading the whole source file, this will natually cause any clients with unwritten data to flush their caches when their write-extent locks are cancelled. Once the copy is completed (optionally verifying the data checksum after flushing the client cache?) the llapi_layout_swap() function is called, and the "new" open-unlinked file descriptor layout (which now points to the old objects) is closed, causing those objects to be destroyed. The exclusive lock can be dropped.
If the MDS does not support MDS_SWAP_LAYOUTS then lfs migrate should return an -EOPNOTSUPP error, so that users are aware that atomic layout swap is not available.
The lfs_migrate script should call the lfs migrate command to do the migrate/copy (instead of rsync + mv). but lfs_migrate probably needs to fall back to rsync+mv again. The lfs_migrate script has not previously guaranteed atomic migration, so it should continue to work using rsync+mv as it has in the past if "lfs migrate" returns EOPNOTSUPP, with a comment to the effect that this functionality should be removed after Lustre 2.10 or so.
Attachments
Issue Links
- is related to
-
-

- Resolved
-

Activity
+1 on this being a very cool thing. "lfs migrate [--block]" allows in filesystem data migration. Is there a lustre-test for this?
Before this bug can be closed, we need to update the user manual to describe this feature.
With the landing of the latest patch, is it now safe to do "lfs migrate [--block]" on a file that is in use and actively undergoing IO?
Yes.
With the landing of the latest patch, is it now safe to do "lfs migrate [--block]" on a file that is in use and actively undergoing IO? If yes, this would be a great feature coming from the HSM to announce for 2.4, even though the full HSM functionality is not yet available.
I think it would make sense to ensure that exclusive open has the same semantics as leases, so that we do not need to implement something similar but slightly different in the future. I believe they have a similar semantic if notifying the client, but do not necessarily revoke the client lease immediately.
To be honesty, I think we could get fairly similar behavior with regular MDS DLM locks, if they could be dropped asynchronously if there is a failure on one of the OSTs. The client would get a DLM layout lock, register a callback to userspace for any blocking callback event, and if the userspace thread isn't responsive in time then the lock is cancelled anyway (as it is today) and e.g. the open file handle is invalidated. That gives userspace some limited time to finish or snort migration, and in almost all cases this will be sufficient, just like for regular clients.
This was actually in the original migration design at https://bugzilla.lustre.org/show_bug.cgi?id=13182 and related bugs.
Thoughts?
This is a first tentative because it does not add the support of O_EXCL as requested by Jinshan
Exclusive open is lustre specific which is not simply O_EXCL. We should make it clear at initial start otherwise people will be confused.
Andreas, would you suggest a name please?
For use by the "lfs_migrate" script, this is sufficient for use today, since that script is already not safe for files being modified. It is better than the simple cp + checksum method, since it preserves the inode numbers and would also keep open file handles for read or write, so long as they are not actively writing during migration.
"lfs migrate" probably needs a comment in the usage message to indicate it is not totally safe for files that are actively undergoing IO. It might also make sense to have an upper limit on the number of times it will try to migrate the file in the loop when the data version has changed, and continue to try any other files. It should save an error if this happens (maybe EBUSY) and return it at the end, so that it is clear to the user that the migrate was not totally successful.
Patch at http://review.whamcloud.com/5620
This is a first tentative because it does not add the support of O_EXCL as requested by Jinshan
let's start with lfs migrate, have it working and we will ask to the list later
There is sanity.sh test_56w(), though it doesn't appear this verifies the data...