Details
-
Improvement
-
Resolution: Won't Fix
-
 Blocker
Blocker
-
None
-
Lustre 2.4.0
-
RHEL 6.2
-
2828
Description
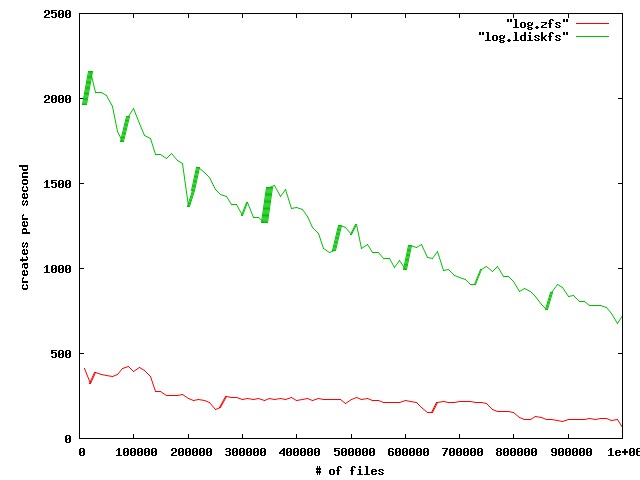
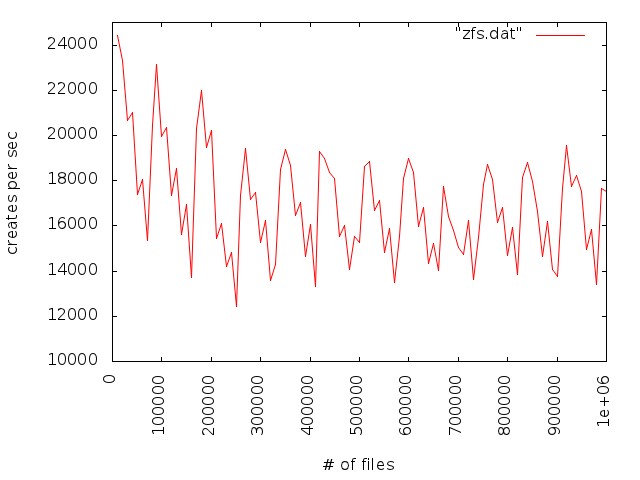
We observe poor file creation rate performance with a zfs backend. The attached jpeg was generated using the createmany benchmark creating 1 million files in a single directory. Files created per second were reported for every 10,000 files created. The green line shows results for Lustre 2.1 and ldiskfs backend. The red line was with ZFS on Orion.
The benchmark was run on the same hardware for both ldisks and ZFS:
MDT: 24 GB RAM, 8 200GB SSD drives in two external SAS-2 enclosures
(Linux MD-RAID10 for ldiskfs, 1 zpool with 8 mirrored pairs for zfs)
OSS: 2 OSS nodes (3 8TB* OSTs each for ldiskfs, 1 72TB OST each for ZFS)
OST: Netapp 60 drive enclosure, 6 24 TB RAID6 LUNs, 3 TB SAS drives, dual 4X QDR IB connections to each OST
Network: 20 Gb/sec 4X DDR IB
*LUNs were partitioned for ldiskfs for compatibility reasons
Attachments
Issue Links
- duplicates
-
LU-2600 lustre metadata performance is very slow on zfs
-

- Resolved
-

Activity
Roughly, I see about 6500 creates per second from ior when all 768 OST are available on Sequoia. Rates are lower when not all 768 are available.
Christopher, could you describe current status please? any numbers to share?
There is still work needed in this area. Moving to an LU ticket would be fine.
Brian, Ned, do you think we can close the ticket? another option is to make it LU-XXXX
Right, since we have a pretty good idea what's going on here I'd rather see us fix some of the remaining stability issues we've observed through real usage. I'll troll our logs from the last two weeks and email a list which should help you guys prioritize.
Well, we definitely will need to do something about the file create performance. But, Lustre might be off the hook for the time being. From the information we have currently, we'll need to make some modifications on the ZFS backend in order to increase the create rate.
The issue arises when the ZFS ARC is "full" (or hit the metadata limit in this case) and thus needs to start evicting buffers. Since the evict function takes giant locks on the state list mutexes, all other traffic needing to use those state mutexes obviously will block. Lustre doesn't have much say in this matter, so the "fix" will need to come from within ZFS.
One possible solution would be to proactively pitch metadata buffers from the cache when the system is idle. This would give enough free ARC space to allow quick bursts of creates. For example, an application would be able to create ~1M files at the ~6K/s rate. Then in the background, the ARC would be pruned so it doesn't hit the metadata limit (and drop to the slower rate) when the next ~1M burst happens.
Of course this doesn't fix the sustained rate. The fix for that would be much more invasive and would require finer grained locking over the lists.
a lot of interesting information! thanks Prakash. are you saying this should not be our focus at the moment?
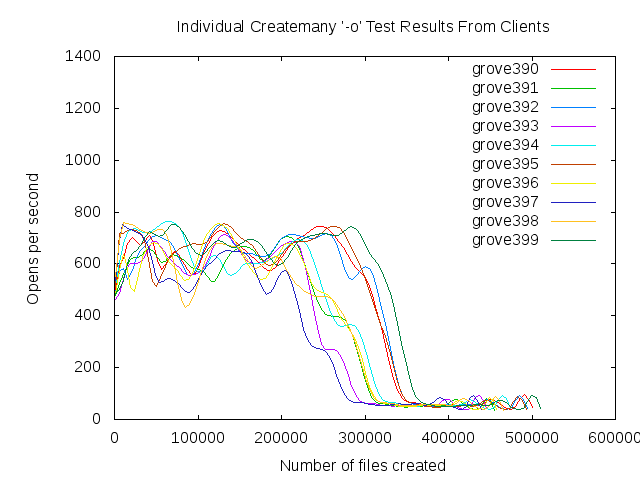
I ran the "createmany" test on 10 client nodes all creating files in separate directories. The exact test run was essentially:
pdsh -w grove[390-399] '/tmp/createmany -o -g -i 1000 /p/lstest/surya1/ori434/run1/`hostname`/%d 1000000'
- clients.png - A graph of the create rate as reported by each client "createmany" test vs. the total number of files that individual client has created
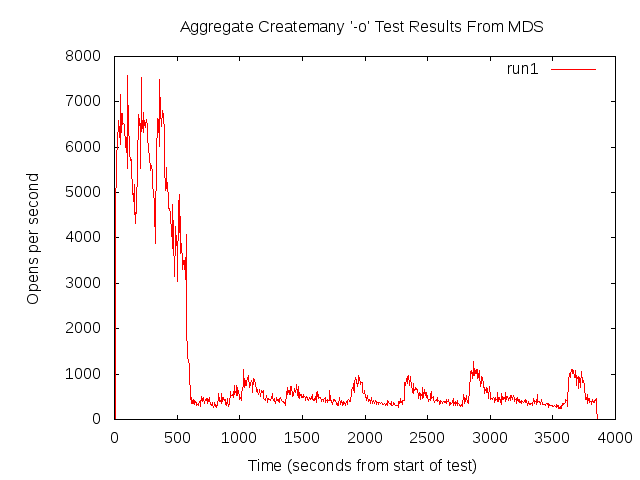
- mdstats.png - A graph of the aggregate number of creates per second as reported by the MDS vs. Time. This value was scraped from the "md_stats" /proc entry on the MDS.
- ori434-run1.tar.bz2 - A tarball containing all the results and graphs.
Alex,
IIRC, we chalked the create rate degrading over time to a deficiency in the lu_site hash function implementation. This has since been fixed and landed:
commit 23d5254c8d607a0ae1065853011ecfc82f0543a2
Author: Liang Zhen <liang@whamcloud.com>
Date: Tue Mar 29 16:44:41 2011 +0800
LU-143 fid hash improvements
Current hash function of fid is not good enough for lu_site and
ldlm_namespace.
We have to use two totally different hash functions to hash fid into
hash table with millions of entries.
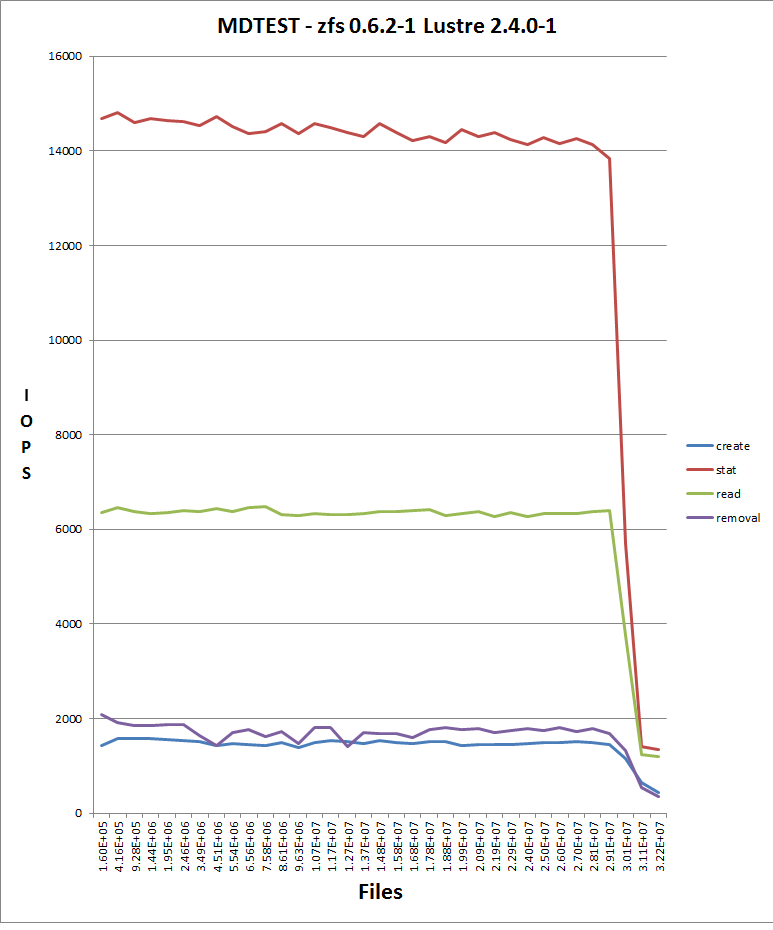
As far as the current state for our MDS create rate performance, we think there are two distinct states which the MDS gets in. The state where the ARC has not hit it's metadata limit, and the state when it has hit the metadata limit. Create rates are much better prior to hitting the limit.
Once the limit is hit, we believe our biggest bottle neck lies withing ZFS. Once this happens, the ARC will be forced to pitch data from it's cache. In the process it calls the arc_evict function, which is pretty heavy handed with respect to the locking it does. It takes the state mutex and the evicted state mutex and holds those locks for the majority of the function:
1671 static void *
1672 arc_evict(arc_state_t *state, uint64_t spa, int64_t bytes, boolean_t recycle,
1673 arc_buf_contents_t type)
1674 {
...
1687 mutex_enter(&state->arcs_mtx);
1688 mutex_enter(&evicted_state->arcs_mtx);
...
1772 mutex_exit(&evicted_state->arcs_mtx);
1773 mutex_exit(&state->arcs_mtx);
...
1807 }
The profiling we've done does not show the MDS being CPU bound. Specifically, top shows the arc_adapt and txg_sync threads as the top CPU offenders (but 90% of cpu still idle), and oprofile shows the arc_evict as very high in the list of CPU offenders but only at about 5% of the cpu:
samples % image name app name symbol name 469692 5.7936 zfs.ko zfs.ko lzjb_decompress 409723 5.0538 zfs.ko zfs.ko arc_evict 394668 4.8681 vmlinux vmlinux intel_idle 393170 4.8497 vmlinux vmlinux mutex_spin_on_owner 375095 4.6267 spl.ko spl.ko taskq_thread 213346 2.6316 vmlinux vmlinux mutex_lock 190386 2.3484 zfs.ko zfs.ko lzjb_compress 120682 1.4886 spl.ko spl.ko spl_kmem_cache_alloc 117026 1.4435 vmlinux vmlinux poll_idle 116807 1.4408 vmlinux vmlinux mutex_unlock 110453 1.3624 spl.ko spl.ko __taskq_dispatch_ent 100957 1.2453 vmlinux vmlinux find_busiest_group 99320 1.2251 vmlinux vmlinux kfree 96255 1.1873 obdclass.ko obdclass.ko lu_site_purge 81324 1.0031 libcfs.ko libcfs.ko cfs_hash_spin_lock 78966 0.9740 vmlinux vmlinux schedule
Brian has also mention that he has seen similar reports of the metadata performance degrading once the ARC's metadata limit is reached on workloads entirely through ZFS/ZPL alone.
So I think the work that needs to be done next in order to increase our sustained and/or burst create rate performace will be in the ZFS code.
As a follow up comment, I'll post the data from the createmany test I ran earlier today. Along with some graphs of the performance numbers.
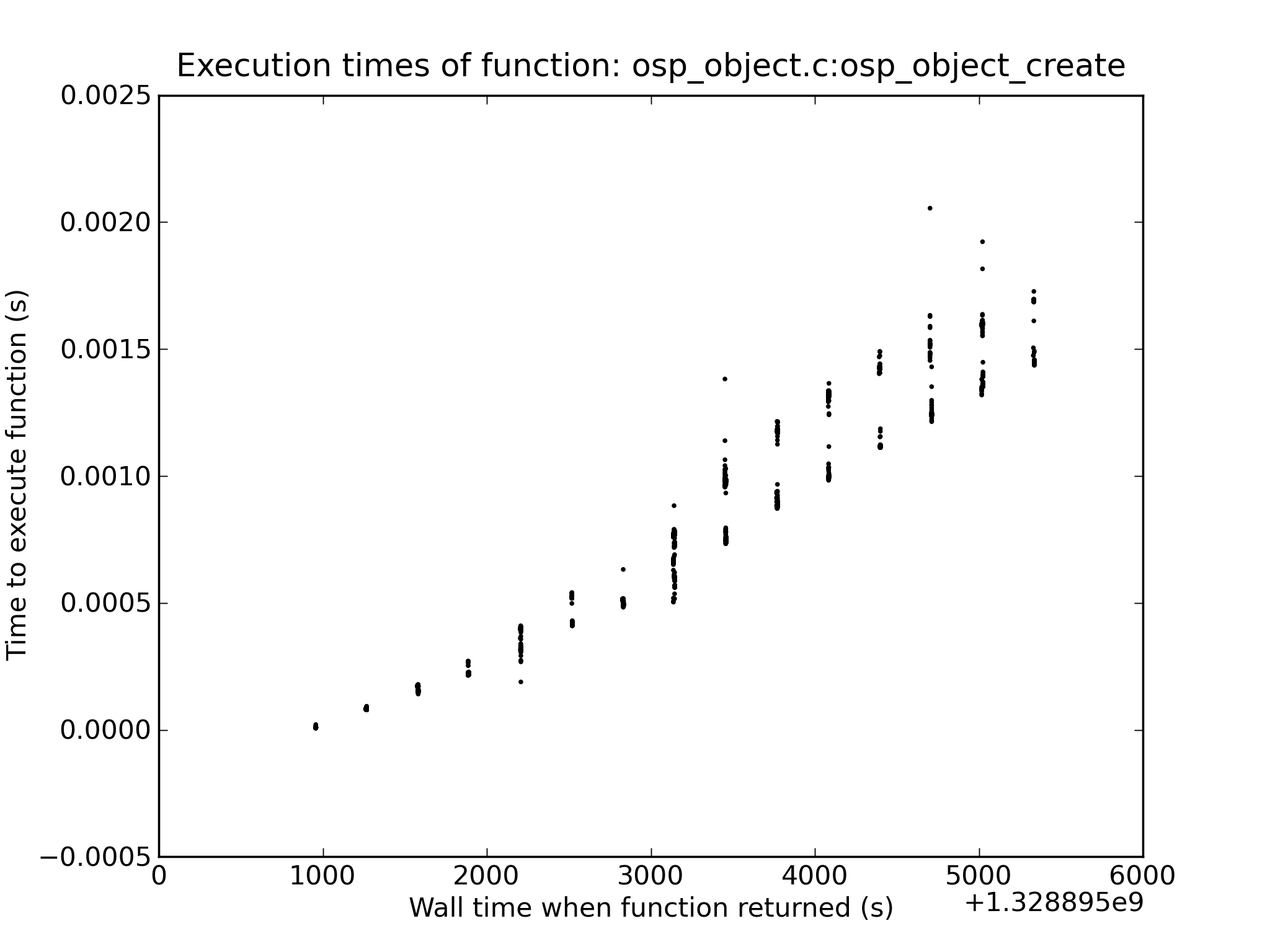
This bug is for OST object creation performance,
LU-2600is for MDT object create performance. Will likely be fixed together, but may be different in some way.