Details
-
Improvement
-
Resolution: Won't Fix
-
 Blocker
Blocker
-
None
-
Lustre 2.4.0
-
RHEL 6.2
-
2828
Description
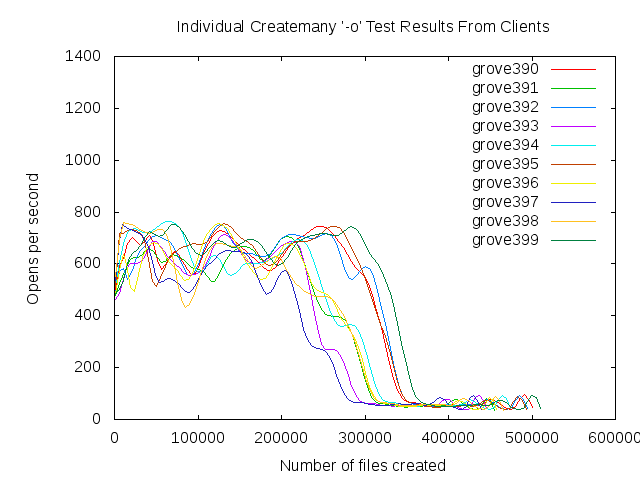
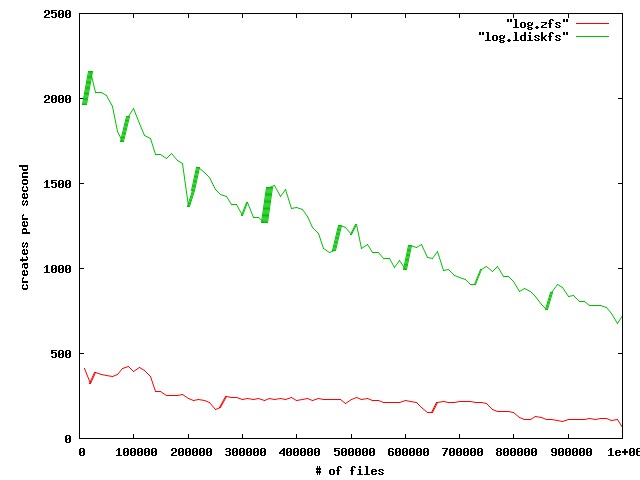
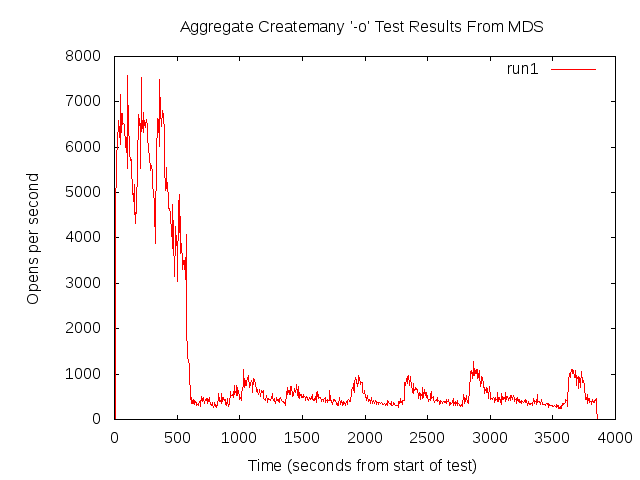
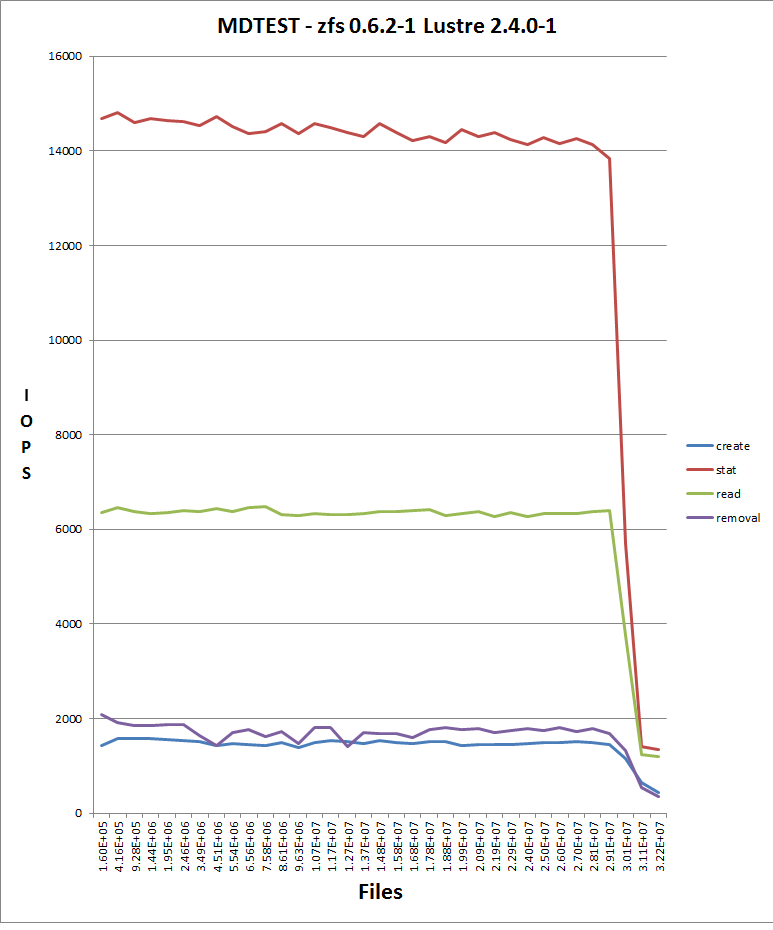
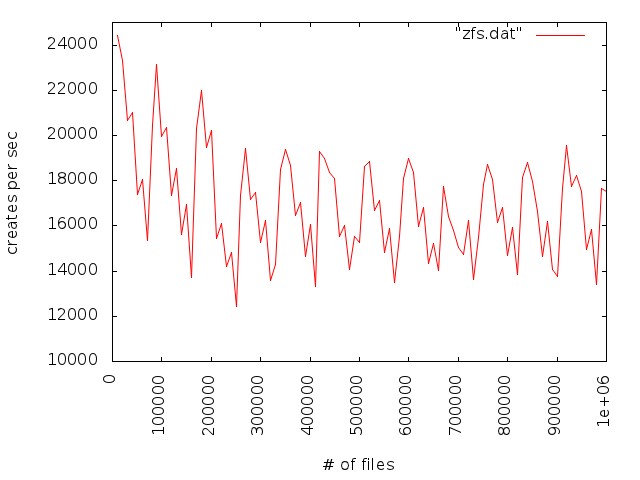
We observe poor file creation rate performance with a zfs backend. The attached jpeg was generated using the createmany benchmark creating 1 million files in a single directory. Files created per second were reported for every 10,000 files created. The green line shows results for Lustre 2.1 and ldiskfs backend. The red line was with ZFS on Orion.
The benchmark was run on the same hardware for both ldisks and ZFS:
MDT: 24 GB RAM, 8 200GB SSD drives in two external SAS-2 enclosures
(Linux MD-RAID10 for ldiskfs, 1 zpool with 8 mirrored pairs for zfs)
OSS: 2 OSS nodes (3 8TB* OSTs each for ldiskfs, 1 72TB OST each for ZFS)
OST: Netapp 60 drive enclosure, 6 24 TB RAID6 LUNs, 3 TB SAS drives, dual 4X QDR IB connections to each OST
Network: 20 Gb/sec 4X DDR IB
*LUNs were partitioned for ldiskfs for compatibility reasons
Attachments
Issue Links
- duplicates
-
LU-2600 lustre metadata performance is very slow on zfs
-

- Resolved
-
