Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Lustre 2.4.2
-
3
-
13336
Description
While migrating a file with "lfs migrate", if a process tries to truncate the file, both lfs migrate and truncating processes will deadlock.
This will result in both processes never finishing (unless it is killed) and watchdog messages saying that the processes did not progress for the last XXX seconds.
Here is a reproducer:
[root@lustre24cli ~]# cat reproducer.sh
#!/bin/sh
FS=/test
FILE=${FS}/file
rm -f ${FILE}
# Create a file on OST 1 of size 512M
lfs setstripe -o 1 -c 1 ${FILE}
dd if=/dev/zero of=${FILE} bs=1M count=512
echo 3 > /proc/sys/vm/drop_caches
# Launch a migrate to OST 0 and a bit later open it for write
lfs migrate -i 0 --block ${FILE} &
sleep 2
dd if=/dev/zero of=${FILE} bs=1M count=512
Once the last dd tries to open the file, both lfs and dd processes stay forever with this stack:
lfs stack:
[<ffffffff8128e864>] call_rwsem_down_read_failed+0x14/0x30 [<ffffffffa08d98dd>] ll_file_io_generic+0x29d/0x600 [lustre] [<ffffffffa08d9d7f>] ll_file_aio_read+0x13f/0x2c0 [lustre] [<ffffffffa08da61c>] ll_file_read+0x16c/0x2a0 [lustre] [<ffffffff811896b5>] vfs_read+0xb5/0x1a0 [<ffffffff811897f1>] sys_read+0x51/0x90 [<ffffffff8100b072>] system_call_fastpath+0x16/0x1b [<ffffffffffffffff>] 0xffffffffffffffff
dd stack:
[<ffffffffa03436fe>] cfs_waitq_wait+0xe/0x10 [libcfs] [<ffffffffa04779fa>] cl_lock_state_wait+0x1aa/0x320 [obdclass] [<ffffffffa04781eb>] cl_enqueue_locked+0x15b/0x1f0 [obdclass] [<ffffffffa0478d6e>] cl_lock_request+0x7e/0x270 [obdclass] [<ffffffffa047e00c>] cl_io_lock+0x3cc/0x560 [obdclass] [<ffffffffa047e242>] cl_io_loop+0xa2/0x1b0 [obdclass] [<ffffffffa092a8c8>] cl_setattr_ost+0x208/0x2c0 [lustre] [<ffffffffa08f8a0e>] ll_setattr_raw+0x9ce/0x1000 [lustre] [<ffffffffa08f909b>] ll_setattr+0x5b/0xf0 [lustre] [<ffffffff811a7348>] notify_change+0x168/0x340 [<ffffffff81187074>] do_truncate+0x64/0xa0 [<ffffffff8119bcc1>] do_filp_open+0x861/0xd20 [<ffffffff81185d39>] do_sys_open+0x69/0x140 [<ffffffff81185e50>] sys_open+0x20/0x30 [<ffffffff8100b072>] system_call_fastpath+0x16/0x1b [<ffffffffffffffff>] 0xffffffffffffffff
Attachments
Issue Links
- is related to
-
-
- Resolved
-
-
-

- Resolved
-
-
-

- Resolved
-
- is related to
-
-
- Resolved
-
Activity
Cf. the new patchset.
Indeed, I do see the race window between llapi_lease_put() and llapi_fswap_layouts() but I can't see any userland API that would allow us to get rid of it. Am I missing something? You're stressing the need to do operations atomically, do you have something in mind, like making the SWAP_LAYOUT ioctl lease-aware?
We have to make `put lease', `swap layout', and `close source file' in one atomic operation. Otherwise, if the source is opened for writing after `put lease' and generate some dirty pages, it will produce data corruption.
Thanks Jinshan.
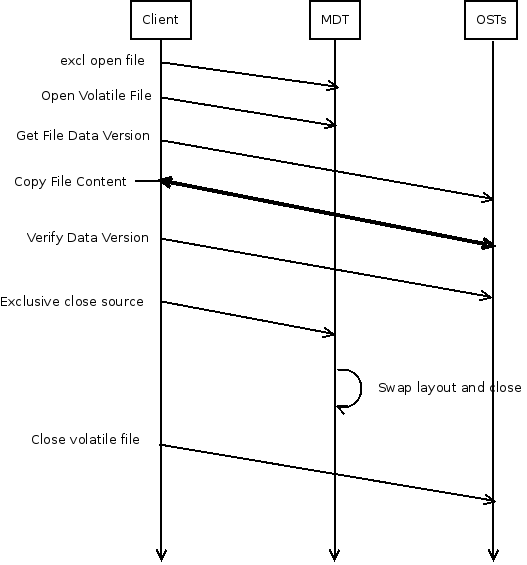
I still have a question regarding when to check data version. In which case could it fail if we both get and check it under the file lease? Also swap layout will perform a dataversion check. Is the following sequence flawed?
- open source file
- get lease
- open volatile
- get data version
- copy file content
- put lease
- swap layout (pass in data version for check)
- close volatile
- close source file
Please check the attachment for the implementation of migration.
The procedure is a little bit like HSM release where close and swap layout should be an atomic operation. Also, you need to check if the lease is valid in the middle of data copying periodically therefore data copying can abort if the file is being opened by others.
Please take a look at it and I'll be happy to answer questions.
OK, CEA will do it.
Could you confirm some behaviour of open lease to be sure we are in line. There is only exclusive open lease for now? When lease are revoked by concurrent access?
That's true, Aurelien. As long as the migration was implemented by CEA, would it be possible for CEA to pick it up again to reimplement it with open lease?
Jinshan
I see no objection to replacing grouplock-based code with an open-lease mechanism. Current code was using this lock because open lease did not exist as that time and we were advised to do this this way as they was no mechanism to protect from concurrent access. I think it will be cleaner.
It's a good chance to reimplement migration with open lease.
Aurelien and JC, do you have any inputs on this?
No, there is no API in user space ready to use.
Yes, similar. Instead of making SWAP_LAYOUT lease-aware, what we need is to make lease SWAP-LAYOUT aware.
When we release a lease, a CLOSE RPC will be sent to MDT. We're going to pack the FID of volatile file into the RPC, with a special bias (similar to MDS_HSM_RELEASE, please check ll_close_inode_openhandle() for 'op_data->op_bias |= MDS_HSM_RELEASE', and mdt_hsm_release()), for example, MDS_CLOSE_SWAP_LAYOUT to tell MDT that we want to unlock the release and swap the layout. We're going to extend `struct close_data' to include those information. And the ioctl() of LL_IOC_SET_LEASE with F_UNLCK will be extended as well.
It's totally fine for me to write a design but I think you have understood the problem and are capable of doing it yourself, based on your questions above.