Details
-
Bug
-
Resolution: Duplicate
-
 Blocker
Blocker
-
Lustre 2.6.0
-
3
-
13338
Description
After commit 586e95a5b3f7b9525d78e7efc9f2949387fc9d54 we have significant performance degradation in master. The following pictures show the regress measured on Xeon Phi:
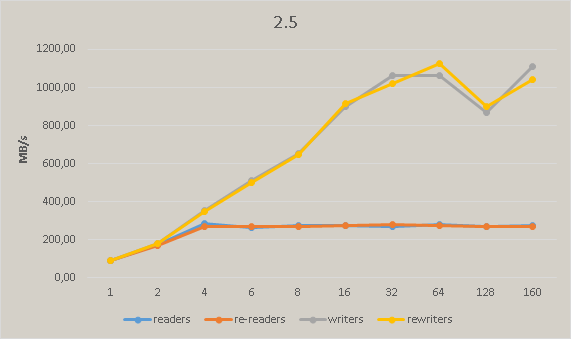
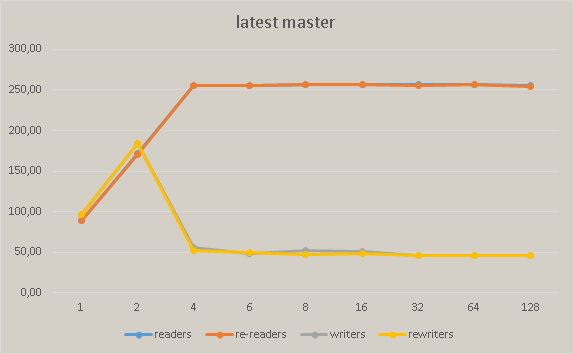
{kind=link}
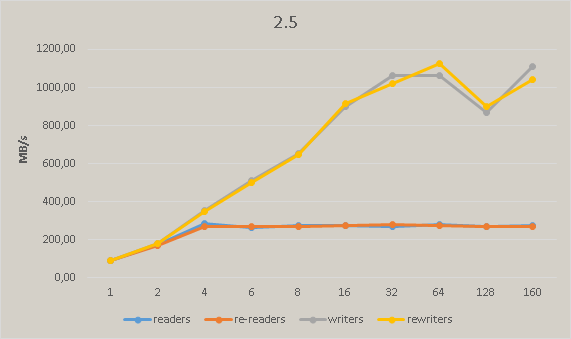{kind=link}
{kind=link}
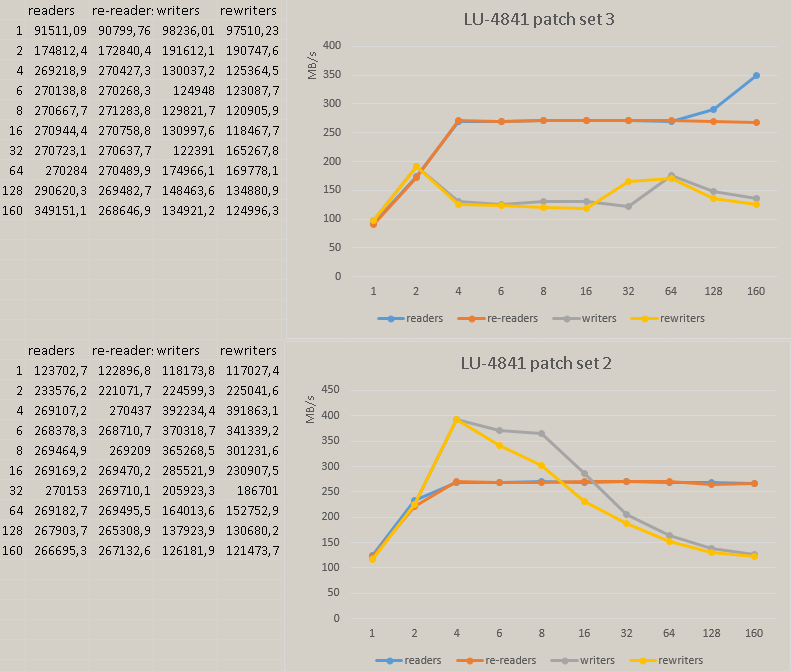{kind=link}
{kind=link}