Details
-
Bug
-
Resolution: Cannot Reproduce
-
 Minor
Minor
-
None
-
Lustre 2.5.2
-
None
-
3
-
15580
Description
This morning some of our clients were hanging (others had not been checked at that time), the active MDS was unresponsive and flooding the console with stack traces. We had to fail over to the second MDS to get the file system back.
Looking at the system logs, we see a large number of these messages:
kernel: socknal_sd00_02: page allocation failure. order:2, mode:0x20 all followed by many stack traces, full log attached. Our monitoring is showing that the memory was mainly used by buffers but this had been the case for all of last week already and was stable and only slowly increasing. After the restart the memory used by buffers has quickly increase to about 60% and currently seems to be stable about there...
Just before these page allocation failure messages we noticed a few client reconnect messages, but have not been able to find any network problems so far. Since the restart of the MDT, no unexpected client reconnects have been seen.
We are running lustre 2.5.2 + 4 patches as recommended in LU-5529 and LU-5514.
We've been hammering the MDS a bit since the upgrade, both creating files, stating many files/directories from many clients etc and removing many files, but I would still expect the MDS not to fall over like this.
Is this a problem/memory leak in Lustre or something else? Could it be related different compile options when compiling Lustre? We did compile the version on the MDS in house with these patches and there is always a chance we didn't quite use the same compile time options that the automatic build process would use...
What can we do to debug this further and avoid it in the future?
Attachments
Issue Links
Activity
two dump files collected while I suspect the problem was ongoing. manual_dump.txt has been collected while I was experiencing the problem.
MDT log from the time after failing over the MDT to this machine until now.
Andreas, All,
the original issue that all/some clients appear to be hanging on most metadata operations is back, this time the memory on the MDS doesn't look bad, so that might have been something else.
The symptoms now that we're taking more time in debugging it appear to be that many clients appear to be hanging for example when doing 'ls -l' on some directories (not the top level directory of the file system). The ls will eventually complete but it takes long enough for users to phone us and a detailed conversation about what they're doing, where, us looking into the machine and it still hasn't completed... This is even for directories with only 2 subdirectories and no files.
time ls -l /mnt/lustre03/i04 total 8 drwxrwxr-x+ 11 root dls_sysadmin 4096 Aug 14 10:52 data drwxrwsr-x+ 10 epics_user i04_data 4096 Aug 2 2011 epics real 4m48.799s user 0m0.001s sys 0m0.001s
The MDS is reporting a number of these messages Lustre: lock timed out (enqueued at 1410413746, 300s ago along with a few threads completing after 200+s, system load is currently around 70, in top there's three processes at the top usually in state 'D': flush-253:6, kcopyd , jbd2/dm-6-8 (see top output below).
It all seems to have started sometime last night with this Sep 11 02:26:13 cs04r-sc-mds03-01 kernel: INFO: task mdt_rdpg00_000:12042 blocked for more than 120 seconds. nothing in the logs after that until 04:00 but it seems to have goten worse after that.
I can't rule out hardware issues on the disk backend but so far have not found any error messages that confirm that.
Syslog from for the relevant time the MDS will be attached, here's an extract. There's nothing Lustre or network related in syslog on the clients or the OSSes.
Sep 11 04:00:10 cs04r-sc-mds03-01 kernel: LNet: Service thread pid 22232 completed after 217.24s. This indicates the system was overloaded (too many service threads, or there were not enough hardware resources). Sep 11 04:00:10 cs04r-sc-mds03-01 kernel: LNet: Skipped 7 previous similar messages Sep 11 04:47:43 cs04r-sc-mds03-01 kernel: LustreError: 0:0:(ldlm_lockd.c:344:waiting_locks_callback()) ### lock callback timer expired after 151s: evicting client at 10.144.140.46@o2ib ns: mdt-lustre03-MDT0000_UUID lock: ffff880d7abef3c0/0x4a9a61dbe320f47a lrc: 3/0,0 mode: PR/PR res: [0x4a40692:0xb304ffb3:0x0].0 bits 0x13 rrc: 3 type: IBT flags: 0x60200000000020 nid: 10.144.140.46@o2ib remote: 0xc6d2a2809bd5a9f1 expref: 84365 pid: 20014 timeout: 4398798140 lvb_type: 0 Sep 11 04:47:43 cs04r-sc-mds03-01 kernel: LustreError: 28875:0:(client.c:1079:ptlrpc_import_delay_req()) @@@ IMP_CLOSED req@ffff8809f7420400 x1478844569897188/t0(0) o104->lustre03-MDT0000@10.144.140.46@o2ib:15/16 lens 296/224 e 0 to 0 dl 0 ref 1 fl Rpc:N/0/ffffffff rc 0/-1 Sep 11 04:47:43 cs04r-sc-mds03-01 kernel: LustreError: 28875:0:(ldlm_lockd.c:662:ldlm_handle_ast_error()) ### client (nid 10.144.140.46@o2ib) returned 0 from blocking AST ns: mdt-lustre03-MDT0000_UUID lock: ffff880168665880/0x4a9a61dbe320f9dd lrc: 1/0,0 mode: --/CR res: [0x4a40695:0xb304ffb6:0x0].0 bits 0x5 rrc: 2 type: IBT flags: 0x64a01000000020 nid: 10.144.140.46@o2ib remote: 0xc6d2a2809bd5aa06 expref: 60513 pid: 12032 timeout: 4398949080 lvb_type: 0 Sep 11 04:49:10 cs04r-sc-mds03-01 kernel: Lustre: lustre03-MDT0000: Client b4d423ad-3219-f806-0fd2-5a2845b5faad (at 10.144.140.46@o2ib) reconnecting Sep 11 04:49:10 cs04r-sc-mds03-01 kernel: Lustre: Skipped 67 previous similar messages Sep 11 05:08:41 cs04r-sc-mds03-01 kernel: LNet: Service thread pid 12048 completed after 321.32s. This indicates the system was overloaded (too many service threads, or there were not enough hardware resources). Sep 11 05:08:41 cs04r-sc-mds03-01 kernel: LNet: Skipped 22 previous similar messages Sep 11 06:09:12 cs04r-sc-mds03-01 kernel: LNet: Service thread pid 12036 completed after 329.22s. This indicates the system was overloaded (too many service threads, or there were not enough hardware resources). Sep 11 06:09:12 cs04r-sc-mds03-01 kernel: LNet: Skipped 1 previous similar message Sep 11 06:40:46 cs04r-sc-mds03-01 kernel: Lustre: lock timed out (enqueued at 1410413746, 300s ago)
We don't know what is triggering this, but at the moment we're still running a few jobs both scanning the file systems, copying data away and deleting files in addition to our normal user jobs, so I would expect the MDT to be a bit busier but not that bad.
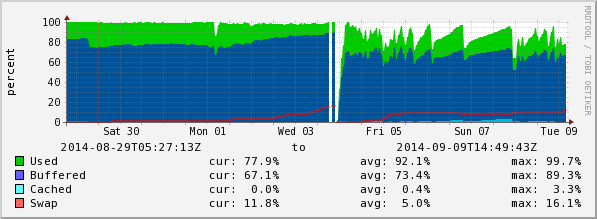
A quick update. Monitoring the memory usage on the MDS over the last week, we've not seen this issue again. See attached memory usage graph, the original issue happened early on Thursday 3, before that buffer memory usage seems to have gone up only, since then the memory/buffer usage has also decreased frequently.
Even though the memory usage wasn't that bad, I took the opportunity of a scheduled maintenance yesterday to collect a debug log just after unmounting the MDT, with malloc added to the debug and debug_mb increased. I've also collected meminfo/slabinfo just before unmounting the MDT, these are attached as well in case there is anything useful in there.
Frederik, it would definitely be useful to see what is in /proc/slabinfo and /proc/meminfo when the MDS is running low on memory. It may be best to just dump this periodically to another system so that it is captured as close to running out of memory as possible if you don't notice this in advance.
In this case we were not able to log into the MDS anymore once we noticed the problem, so couldn't collect these. Equally the serial console was unusable do to the large number of stack traces printed there.
Would it be worth setting the additional debugging and debug log size now and collect the information in /proc/slabinfo and /proc/meminfo just before unmounting during a maintenance window, i.e. before it re-occurs? Then unmount and collect the debug log?
If you run into this case again, please try to log into the MDS and collect /proc/slabinfo and /proc/meminfo to see where all of the memory is allocated.
Ideally, you could also enable the allocation debugging (lctl set_param debug=+alloc), increase the maximum debug log size (lctl set_param debug_mb=200 and then unmount the MDS to see where it is freeing memory, and dump the debug log. Unfortunately this may not capture as much debug logging as one might want because it doesn't have enough memory to store the log itself.
Bobijam
This ticket is perhaps related to the other just assigned to you. Could you please advise
Thanks
Peter
Ah, I think I may now have fixed this immediate problem.
We created a LVM snapshot just before extending the file system earlier this week. We had kept this snapshot around and wanted to keep it for a little longer while we were performing tests on the extended file system. However, searching for information on the kcopyd process, I came across a post to dm-devel about the performance impact of kcopyd. Even though the post was from May 2007, we decided to remove the snapshot and load average immediately started to drop and is now down at around 8, client metadata performance has also recovered, nicely noticeable as jump up for file open rates on the MDT at the time of disabling the snapshot...
I guess the lesson is that snapshots can still have a very large performance impact.