-
Improvement
-
Resolution: Won't Fix
-
 Minor
Minor
-
None
-
Lustre 1.8.7
-
Tested on RHEL 5.6, OFED 1.5.3.1, and Lustre 1.8.6
-
9738
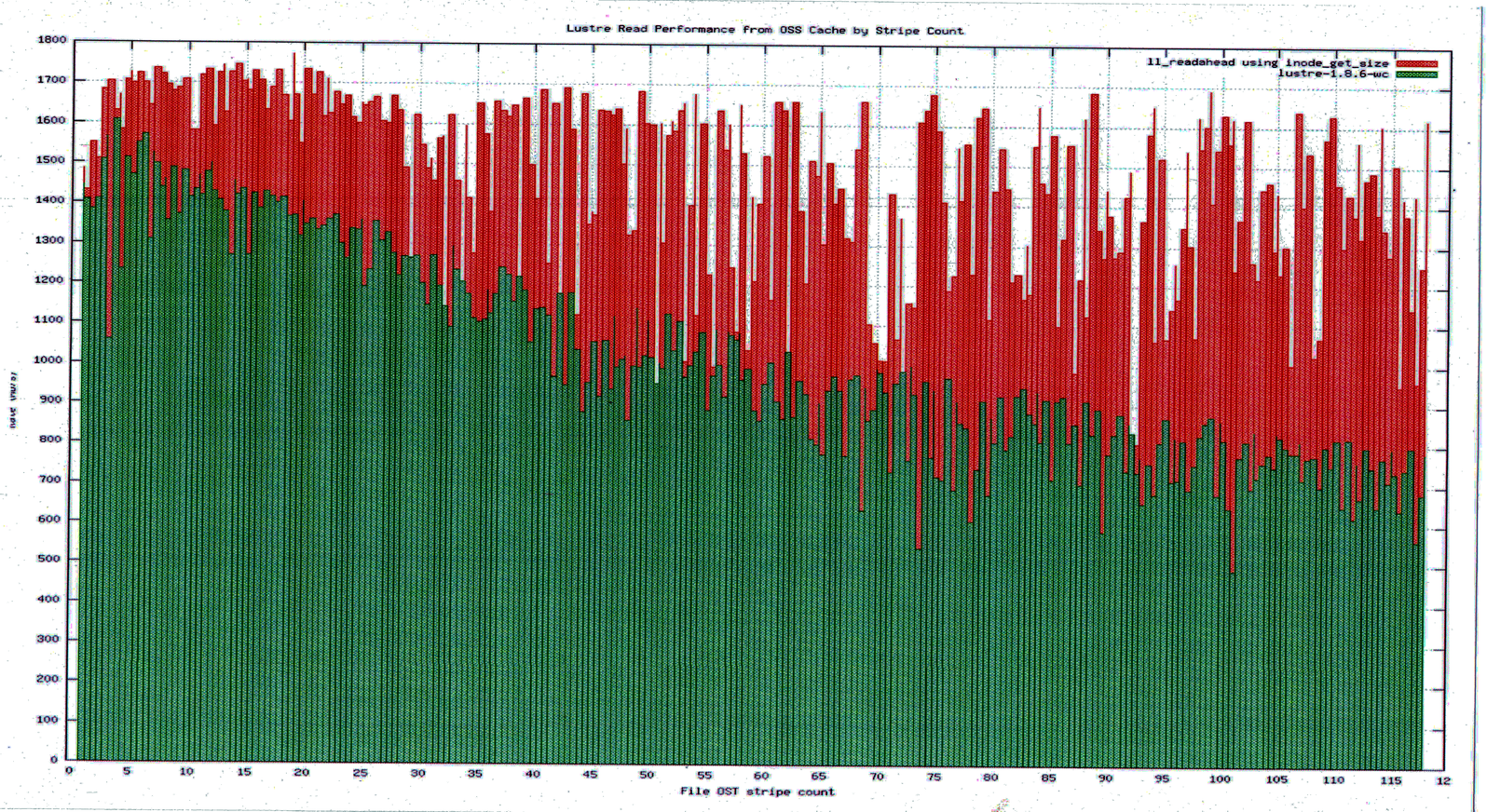
Wile looking at functions with high CPU utilization for LU-1056 we came across lov_stripe_size as one of the top functions for files with larger striping. After looking into this it appears the reason can be summarized as:
With the current read implementation in Lustre 1.8 ll_readpage->ll_readahead->odd_merge_lvb is called for every page of a file at least once. Even if the read ahead pre-fetched the data into cache it still requires a subsequent call to ll_readpage to set the page flags to uptodate. obd_merge_lvb is used to calculate the kms for an inode and calls lov_stripe_size for every stripe in a file. So the larger the striping of a file the larger the overhead in this calculation. To reduce the overhead on calculating the kms i_size_read() could be used for the inode instead of locking the stripe and calling obd_merge_lvb. The inode size should be updated by ll_extent_lock which is called by ll_file_aio_read.
- Trackbacks
-
![[Confluence: Engineering]](/images/icons/generic_link_16.png "[Confluence: Engineering]") Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA
Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA