-
Bug
-
Resolution: Cannot Reproduce
-
 Blocker
Blocker
-
None
-
Lustre 2.12.0
-
None
-
CentOS 7.6, Lustre 2.12.0 clients and servers, some clients with 2.12.0 + patch
LU-11964
-
3
-
9223372036854775807
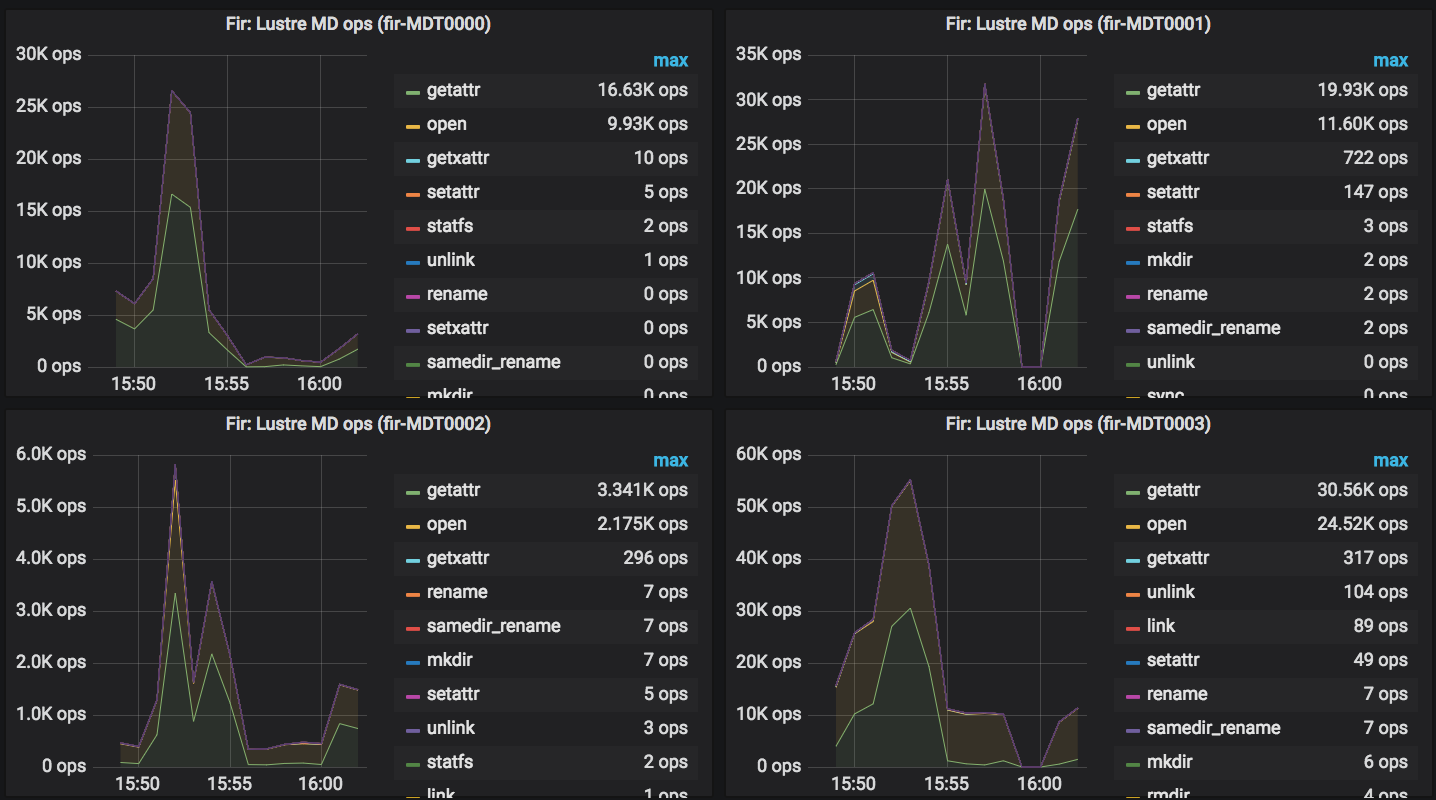
We are having more issues with a full 2.12 production setup on Sherlock and Fir, we can notice sometimes a global filesystem hang, on all nodes, for at least 30 seconds, often more. The filesystem can run fine for 2 hours and then hang during a few minutes. This is impacting production, especially interactive jobs.
These filesystem hangs could be related to compute nodes rebooting and matching messages like the following on the MDTs:
[769459.092993] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1550784454/real 1550784454] req@ffff9cc82f229800 x1625957396013728/t0(0) o104->fir-MDT0002@10.9.101.45@o2ib4:15/16 lens 296/224 e 0 to 1 dl 1550784461 ref 1 fl Rpc:X/0/ffffffff rc 0/-1 [769459.120452] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 1 previous similar message [769473.130314] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1550784468/real 1550784468] req@ffff9cc82f229800 x1625957396013728/t0(0) o104->fir-MDT0002@10.9.101.45@o2ib4:15/16 lens 296/224 e 0 to 1 dl 1550784475 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 [769473.157759] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 1 previous similar message [769494.167799] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1550784489/real 1550784489] req@ffff9cc82f229800 x1625957396013728/t0(0) o104->fir-MDT0002@10.9.101.45@o2ib4:15/16 lens 296/224 e 0 to 1 dl 1550784496 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 [769494.195248] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 2 previous similar messages
I'm not 100% sure but it sounds like when these messages stop on the MDTs, the filesystem comes back online. There is no log on the clients though, as far as I know...
Please note that we're also in the process of fixing the locking issue described in LU-11964 by deploying a patched 2.12.0.
Is this a known issue in 2.12? Any patch available that we can try, or suggestions would be welcomed.
Thanks,
Stephane