Details
-
Bug
-
Resolution: Cannot Reproduce
-
 Blocker
Blocker
-
None
-
Lustre 2.12.0
-
None
-
CentOS 7.6, Lustre 2.12.0 clients and servers, some clients with 2.12.0 + patch
LU-11964
-
3
-
9223372036854775807
Description
We are having more issues with a full 2.12 production setup on Sherlock and Fir, we can notice sometimes a global filesystem hang, on all nodes, for at least 30 seconds, often more. The filesystem can run fine for 2 hours and then hang during a few minutes. This is impacting production, especially interactive jobs.
These filesystem hangs could be related to compute nodes rebooting and matching messages like the following on the MDTs:
[769459.092993] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1550784454/real 1550784454] req@ffff9cc82f229800 x1625957396013728/t0(0) o104->fir-MDT0002@10.9.101.45@o2ib4:15/16 lens 296/224 e 0 to 1 dl 1550784461 ref 1 fl Rpc:X/0/ffffffff rc 0/-1 [769459.120452] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 1 previous similar message [769473.130314] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1550784468/real 1550784468] req@ffff9cc82f229800 x1625957396013728/t0(0) o104->fir-MDT0002@10.9.101.45@o2ib4:15/16 lens 296/224 e 0 to 1 dl 1550784475 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 [769473.157759] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 1 previous similar message [769494.167799] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1550784489/real 1550784489] req@ffff9cc82f229800 x1625957396013728/t0(0) o104->fir-MDT0002@10.9.101.45@o2ib4:15/16 lens 296/224 e 0 to 1 dl 1550784496 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 [769494.195248] Lustre: 21751:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 2 previous similar messages
I'm not 100% sure but it sounds like when these messages stop on the MDTs, the filesystem comes back online. There is no log on the clients though, as far as I know...
Please note that we're also in the process of fixing the locking issue described in LU-11964 by deploying a patched 2.12.0.
Is this a known issue in 2.12? Any patch available that we can try, or suggestions would be welcomed.
Thanks,
Stephane
Attachments
Issue Links
Activity
Would you be able to tar up and attach dmesg from all your MDSes?
Stephane,
Have you changed any settings related to adaptive timeouts (AT_MIN, AT_MAX) or obd_timeout? (Not suggesting you change these yet - Just asking.)
Wasn't very long... the client was 10.8.20.15@o2ib6 in that case:
fir-md1-s1 (MDT0000, MDT0002):
Mar 12 12:38:48 fir-md1-s1 kernel: Lustre: 31416:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1552419520/real 1552419520] req@ffff8b8c3445ef00 x1627815889426544/t0(0) o106->fir-MDT0000@10.8.20.15@o2ib6:15/16 lens 296/280 e 0 to 1 dl 1552419527 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 Mar 12 12:38:48 fir-md1-s1 kernel: Lustre: 31416:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 346 previous similar messages Mar 12 12:39:30 fir-md1-s1 kernel: LustreError: 34992:0:(ldlm_lockd.c:682:ldlm_handle_ast_error()) ### client (nid 10.8.20.15@o2ib6) failed to reply to blocking AST (req@ffff8b798eedd100 x1627815889391920 status 0 rc -110), evict it ns: mdt-fir-MDT0000_UUID lock: ffff8b677f2218c0/0x4cd4038d909bca08 lrc: 4/0,0 mode: PR/PR res: [0x20000560a:0x5ec5:0x0].0x0 bits 0x13/0x0 rrc: 56 type: IBT flags: 0x60200400000020 nid: 10.8.20.15@o2ib6 remote: 0x282f29ed39ed2a33 expref: 78 pid: 31590 timeout: 264509 lvb_type: 0 Mar 12 12:39:30 fir-md1-s1 kernel: LustreError: 138-a: fir-MDT0000: A client on nid 10.8.20.15@o2ib6 was evicted due to a lock blocking callback time out: rc -110 Mar 12 12:39:30 fir-md1-s1 kernel: LustreError: 30507:0:(ldlm_lockd.c:256:expired_lock_main()) ### lock callback timer expired after 154s: evicting client at 10.8.20.15@o2ib6 ns: mdt-fir-MDT0000_UUID lock: ffff8b677f2218c0/0x4cd4038d909bca08 lrc: 3/0,0 mode: PR/PR res: [0x20000560a:0x5ec5:0x0].0x0 bits 0x13/0x0 rrc: 56 type: IBT flags: 0x60200400000020 nid: 10.8.20.15@o2ib6 remote: 0x282f29ed39ed2a33 expref: 79 pid: 31590 timeout: 0 lvb_type: 0 Mar 12 12:40:23 fir-md1-s1 kernel: Lustre: fir-MDT0002: haven't heard from client 9e9c0882-3f15-dd96-7d4f-45564e48c021 (at 10.8.20.15@o2ib6) in 227 seconds. I think it's dead, and I am evicting it. exp ffff8b6b55711000, cur 1552419623 expire 1552419473 last 1552419396 Mar 12 12:40:23 fir-md1-s1 kernel: Lustre: Skipped 3 previous similar messages
fir-md1-s2 (MDT0001, MDT0003):
Mar 12 12:42:45 fir-md1-s2 kernel: Lustre: 31774:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1552419753/real 1552419753] req@ffff8eb94fb2f500 x1627816490690992/t0(0) o104->fir-MDT0003@10.8.20.15@o2ib6:15/16 lens 296/224 e 0 to 1 dl 1552419764 ref 1 fl Rpc:X/0/ffffffff rc 0/-1 Mar 12 12:42:45 fir-md1-s2 kernel: Lustre: 31774:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 7 previous similar messages Mar 12 12:43:29 fir-md1-s2 kernel: LustreError: 31774:0:(ldlm_lockd.c:682:ldlm_handle_ast_error()) ### client (nid 10.8.20.15@o2ib6) returned error from blocking AST (req@ffff8eb94fb2f500 x1627816490690992 status -107 rc -107), evict it ns: mdt-fir-MDT0003_UUID lock: ffff8edbad0469c0/0x60006bf677e1ceee lrc: 4/0,0 mode: PR/PR res: [0x280000401:0x5:0x0].0x0 bits 0x13/0x0 rrc: 821 type: IBT flags: 0x60200400000020 nid: 10.8.20.15@o2ib6 remote: 0x282f29ed39ed259b expref: 7 pid: 31773 timeout: 264501 lvb_type: 0 Mar 12 12:43:29 fir-md1-s2 kernel: LustreError: 138-a: fir-MDT0003: A client on nid 10.8.20.15@o2ib6 was evicted due to a lock blocking callback time out: rc -107 Mar 12 12:43:29 fir-md1-s2 kernel: LustreError: 30984:0:(ldlm_lockd.c:256:expired_lock_main()) ### lock callback timer expired after 56s: evicting client at 10.8.20.15@o2ib6 ns: mdt-fir-MDT0003_UUID lock: ffff8edbad0469c0/0x60006bf677e1ceee lrc: 3/0,0 mode: PR/PR res: [0x280000401:0x5:0x0].0x0 bits 0x13/0x0 rrc: 821 type: IBT flags: 0x60200400000020 nid: 10.8.20.15@o2ib6 remote: 0x282f29ed39ed259b expref: 8 pid: 31773 timeout: 0 lvb_type: 0 Mar 12 12:43:39 fir-md1-s2 kernel: Lustre: fir-MDT0001: haven't heard from client 9e9c0882-3f15-dd96-7d4f-45564e48c021 (at 10.8.20.15@o2ib6) in 227 seconds. I think it's dead, and I am evicting it. exp ffff8ed84f2d8c00, cur 1552419819 expire 1552419669 last 1552419592
I think I got the MDT lock table dumps during that time! Filesystem just unblocked while I was finializing dumping it on fir-md1-s2. Attaching fir-md1-s1_dlmtrace_20190312.log.gz and fir-md1-s2_dlmtrace_20190312.log.gz. Thx.
Hi Patrick!
We have Lai's patch for LU-12037 applied on both MDS now, so...
I'll try to dump the lock tables next time this happens. Thanks!
Stephane,
Are you able to dump the lock tables? Remember that when you did that before, it was actually that DOM/rename related hang (LU-12037), not this issue. Having the full table would be very helpful.
I will take a look at timeouts, this should be adjustable.
Again, filesystem blocked while a node crashed
Mar 12 12:06:02 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1552417555/real 1552417555] req@ffff8b6c796a4b00 x162781588295 Mar 12 12:06:16 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1552417569/real 1552417569] req@ffff8b6c796a4b00 x162781588295 Mar 12 12:06:16 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 1 previous similar message Mar 12 12:06:37 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1552417590/real 1552417590] req@ffff8b6c796a4b00 x162781588295 Mar 12 12:06:37 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 2 previous similar messages Mar 12 12:07:12 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1552417625/real 1552417625] req@ffff8b6c796a4b00 x162781588295 Mar 12 12:07:12 fir-md1-s1 kernel: Lustre: 31329:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 4 previous similar messages Mar 12 12:08:01 fir-md1-s1 kernel: LustreError: 31329:0:(ldlm_lockd.c:682:ldlm_handle_ast_error()) ### client (nid 10.8.10.29@o2ib6) failed to reply to blocking AST (req@ffff8b6c796a4b00 x1627815882950880 status Mar 12 12:08:01 fir-md1-s1 kernel: LustreError: 138-a: fir-MDT0002: A client on nid 10.8.10.29@o2ib6 was evicted due to a lock blocking callback time out: rc -110 Mar 12 12:08:01 fir-md1-s1 kernel: LustreError: 30507:0:(ldlm_lockd.c:256:expired_lock_main()) ### lock callback timer expired after 154s: evicting client at 10.8.10.29@o2ib6 ns: mdt-fir-MDT0002_UUID lock: ffff
During that time, we couldn't ls anywhere on /fir (for about 2 minutes, tested from several nodes and subdirectories). Is there a timeout we could lower to mitigate this?
To come back at our original issue, it happened again today, a node crashed (or rebooted, I'm not sure), anyway, the whole filesystem was blocked for a ~2 minutes, including the Robinhood server (scan completely stopped).
This happened today between Mar 04 15:58 and Mar 04 16:00
MDS fir-md1-s2 MDT0001 / MDT0003 logs:
Mar 04 15:58:34 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1551743903/real 1551743903] req@ffff9e1744f16000 x1627086082608288/t0(0) o104->fir-MDT0003@10.8.15.4@o2ib6:15/16 lens 296/224 e 0 to 1 dl 1551743914 ref 1 fl Rpc:X/0/ffffffff rc 0/-1 Mar 04 15:58:34 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 58 previous similar messages Mar 04 15:58:45 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1551743914/real 1551743914] req@ffff9e1744f16000 x1627086082608288/t0(0) o104->fir-MDT0003@10.8.15.4@o2ib6:15/16 lens 296/224 e 0 to 1 dl 1551743925 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 Mar 04 15:59:07 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1551743936/real 1551743936] req@ffff9e1744f16000 x1627086082608288/t0(0) o104->fir-MDT0003@10.8.15.4@o2ib6:15/16 lens 296/224 e 0 to 1 dl 1551743947 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 Mar 04 15:59:07 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 1 previous similar message Mar 04 15:59:40 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) @@@ Request sent has timed out for slow reply: [sent 1551743969/real 1551743969] req@ffff9e1744f16000 x1627086082608288/t0(0) o104->fir-MDT0003@10.8.15.4@o2ib6:15/16 lens 296/224 e 0 to 1 dl 1551743980 ref 1 fl Rpc:X/2/ffffffff rc 0/-1 Mar 04 15:59:40 fir-md1-s2 kernel: Lustre: 55428:0:(client.c:2132:ptlrpc_expire_one_request()) Skipped 2 previous similar messages Mar 04 16:00:40 fir-md1-s2 kernel: Lustre: fir-MDT0001: haven't heard from client 76418224-15e7-b0fc-3a21-b63821db4ba2 (at 10.8.15.4@o2ib6) in 227 seconds. I think it's dead, and I am evicting it. exp ffff9e0ccbc29400, cur 1551744040 expire 1551743890 last 1551743813 Mar 04 16:00:40 fir-md1-s2 kernel: Lustre: Skipped 1 previous similar message Mar 04 16:00:44 fir-md1-s2 kernel: Lustre: DEBUG MARKER: Mon Mar 4 16:00:44 2019
I'm not sure why the other MDT, fir-md1-s1 (MDT0000/MDT0002) didn't complain at all.
I understand that locking could do such thing, but we've never seen that with previous version of Lustre, and this stops ALL metadata operation on the filesystem, globally.
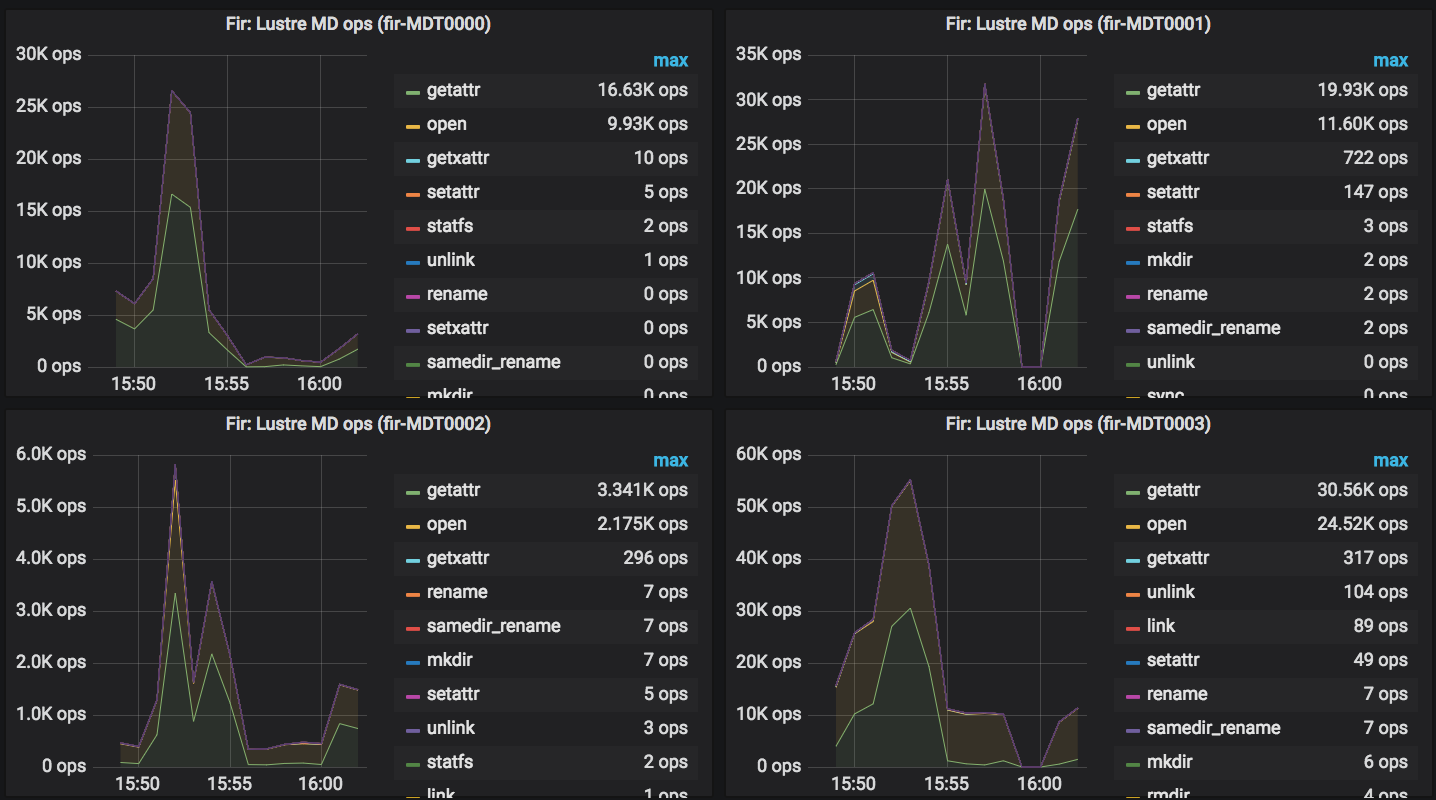
We monitor md ops on the MDTs, and I'm attaching a screenshot of Grafana showing the global drop. Not good... Thanks!
Huh! Stephane, this is a different issue. Can you open a ticket for this with these logs? Looks like a DNE bug of some kind - the MDTs are having connection problems between one another.
Stephane,
Looking in to the timeouts, you can tweak them, but it's a pretty big hammer. We don't want to set these too low or it may cause trouble.
Let's aim for 30 seconds.
On only the MDSes.
You need to set ldlm_enqueue_min to 30, then at_max to 20. (1.5*at_max is the MDS bl_ast timeout. Both are ptlrpc module parameters).
This should reduce your hang time from 150 seconds to 30, and 30 should still be plenty of time.