Creating a new issue as a follow on for LU-14293.
This issue is affecting one production file system and one that's currently in acceptance.
When we stood up the system in acceptance, we ran some benchmarks on the raw block storage, so we're confident that the block storage can provide ~7GB/s read per LUN, with ~65GB/s read across the 12 LUNs in aggregate. What we did not do, however, was run any benchmarks on ZFS after the zpools were created on top of the LUN. Since LNET was no longer our bottleneck, we figured it would make sense to verify the stack from the bottom up, starting with the zpools. We set the zpools to `canmount=on` and changed the mountpoints, then mounted them and ran fio on them. Performance is terrible.
Given that we have another file system running with the exact same tunings and general layout, we also checked that file system in the same manner to much the same results. Since we have past benchmarking results from that file system, we're fairly confident that at some point in the past ZFS was functioning correctly. With that knowledge (and after looking at various zfs github issues) we decided to roll back from zfs 0.8.5 to 0.7.13 to test the performance there. It seems that 0.7.13 is also providing the same results.
I think that there may be potential value in rolling back our kernel to match what it was when we initialized the other file system, as there might be some odd interaction occurring with the kernel version we're running, but I'm not sure.
Here's the results of our testing on a single LUN with ZFS. Keep in mind this LUN can do ~7GB/s at the block level.
- files | read | write
1 file - 396 MB/s | 4.2 GB/s
4 files - 751 MB/s | 4.7 GB/s
12 files - 1.6 GB/s | 4.7 GB/s
And here's the really simple fio we're running to get these numbers:
fio --rw=read --size 20G --bs=1M --name=something --ioengine=libaio --runtime=60s --numjobs=12
We're also noticing some issues where Lustre is eating into those numbers significantly when layered on top. We're going to hold off on debugging that at all until zfs is stable though, as it may just be due to the same zfs issues.
Here's our current zfs module tunings:
- 'metaslab_debug_unload=1' - 'zfs_arc_max=150000000000' - 'zfs_prefetch_disable=1' - 'zfs_dirty_data_max_percent=30' - 'zfs_arc_average_blocksize=1048576' - 'zfs_max_recordsize=1048576' - 'zfs_vdev_aggregation_limit=1048576' - 'zfs_multihost_interval=10000' - 'zfs_multihost_fail_intervals=0' - 'zfs_vdev_async_write_active_min_dirty_percent=20' - 'zfs_vdev_scheduler=deadline' - 'zfs_vdev_async_write_max_active=10' - 'zfs_vdev_async_write_min_active=5' - 'zfs_vdev_async_read_max_active=16' - 'zfs_vdev_async_read_min_active=16' - 'zfetch_max_distance=67108864' - 'dbuf_cache_max_bytes=10485760000' - 'dbuf_cache_shift=3' - 'zfs_txg_timeout=60'
I've tried with zfs checksums on and off with no real change in speed. Screen grabs of the flame graphs from those runs are attached.
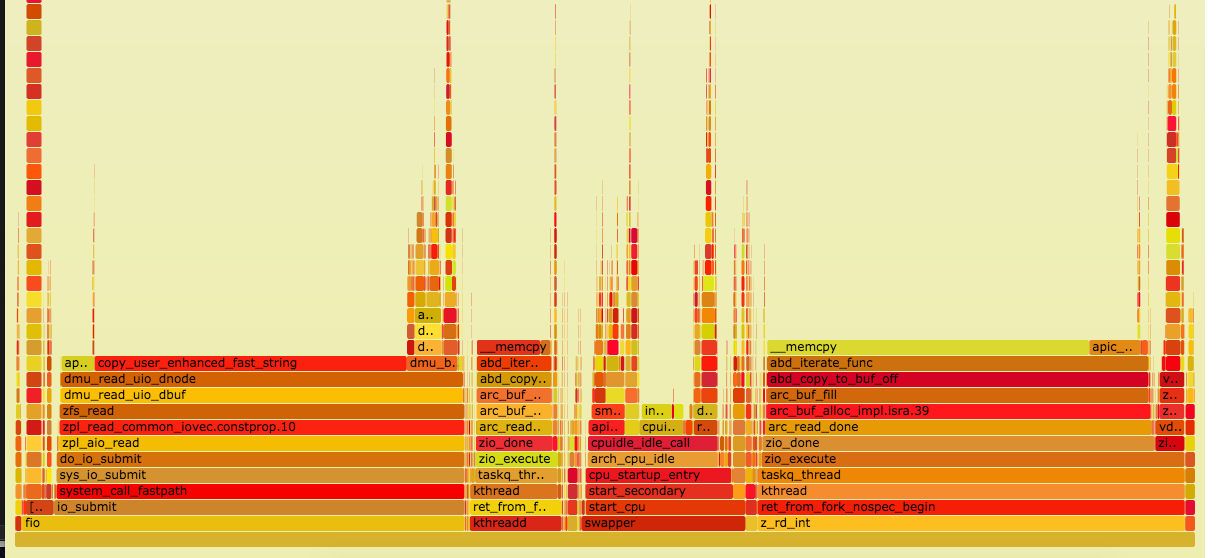
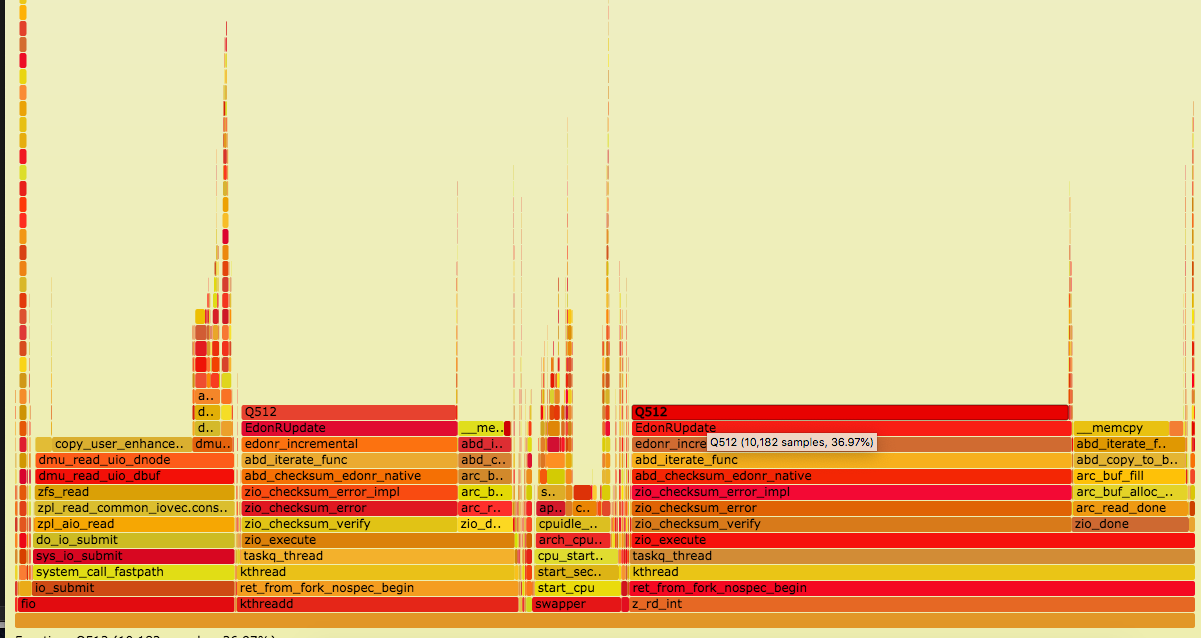
- is related to
-
LU-14293 Poor lnet/ksocklnd(?) performance on 2x100G bonded ethernet
-

- Resolved
-