Description
Creating a new issue as a follow on for LU-14293.
This issue is affecting one production file system and one that's currently in acceptance.
When we stood up the system in acceptance, we ran some benchmarks on the raw block storage, so we're confident that the block storage can provide ~7GB/s read per LUN, with ~65GB/s read across the 12 LUNs in aggregate. What we did not do, however, was run any benchmarks on ZFS after the zpools were created on top of the LUN. Since LNET was no longer our bottleneck, we figured it would make sense to verify the stack from the bottom up, starting with the zpools. We set the zpools to `canmount=on` and changed the mountpoints, then mounted them and ran fio on them. Performance is terrible.
Given that we have another file system running with the exact same tunings and general layout, we also checked that file system in the same manner to much the same results. Since we have past benchmarking results from that file system, we're fairly confident that at some point in the past ZFS was functioning correctly. With that knowledge (and after looking at various zfs github issues) we decided to roll back from zfs 0.8.5 to 0.7.13 to test the performance there. It seems that 0.7.13 is also providing the same results.
I think that there may be potential value in rolling back our kernel to match what it was when we initialized the other file system, as there might be some odd interaction occurring with the kernel version we're running, but I'm not sure.
Here's the results of our testing on a single LUN with ZFS. Keep in mind this LUN can do ~7GB/s at the block level.
- files | read | write
1 file - 396 MB/s | 4.2 GB/s
4 files - 751 MB/s | 4.7 GB/s
12 files - 1.6 GB/s | 4.7 GB/s
And here's the really simple fio we're running to get these numbers:
fio --rw=read --size 20G --bs=1M --name=something --ioengine=libaio --runtime=60s --numjobs=12
We're also noticing some issues where Lustre is eating into those numbers significantly when layered on top. We're going to hold off on debugging that at all until zfs is stable though, as it may just be due to the same zfs issues.
Here's our current zfs module tunings:
- 'metaslab_debug_unload=1' - 'zfs_arc_max=150000000000' - 'zfs_prefetch_disable=1' - 'zfs_dirty_data_max_percent=30' - 'zfs_arc_average_blocksize=1048576' - 'zfs_max_recordsize=1048576' - 'zfs_vdev_aggregation_limit=1048576' - 'zfs_multihost_interval=10000' - 'zfs_multihost_fail_intervals=0' - 'zfs_vdev_async_write_active_min_dirty_percent=20' - 'zfs_vdev_scheduler=deadline' - 'zfs_vdev_async_write_max_active=10' - 'zfs_vdev_async_write_min_active=5' - 'zfs_vdev_async_read_max_active=16' - 'zfs_vdev_async_read_min_active=16' - 'zfetch_max_distance=67108864' - 'dbuf_cache_max_bytes=10485760000' - 'dbuf_cache_shift=3' - 'zfs_txg_timeout=60'
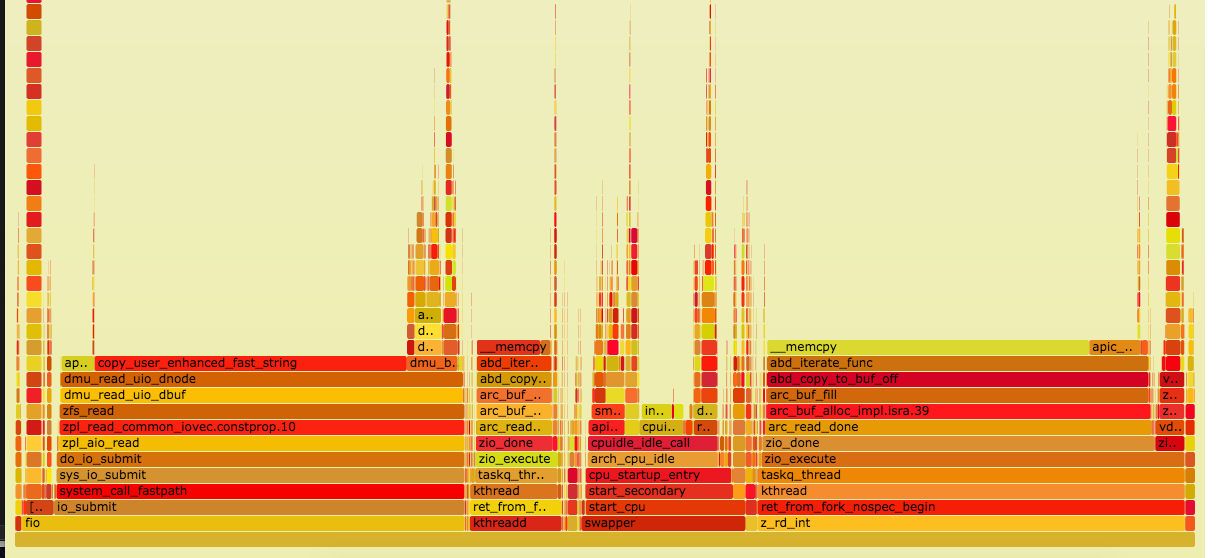
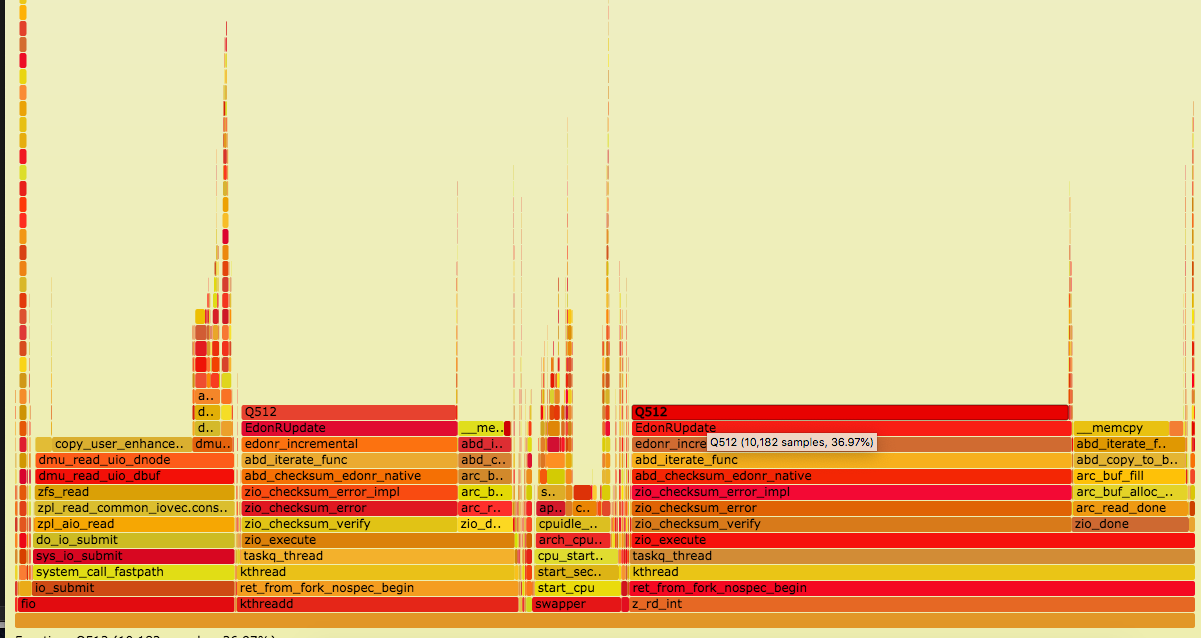
I've tried with zfs checksums on and off with no real change in speed. Screen grabs of the flame graphs from those runs are attached.
Attachments
Issue Links
- is related to
-
LU-14293 Poor lnet/ksocklnd(?) performance on 2x100G bonded ethernet
-

- Resolved
-
Activity
Sorry for the delayed response, we've been working on testing and migrating over to a test system.
Our zfs_vdev_scheduler is currently getting tuned to deadline. We tried setting it to noop, and then tried setting both it and the scheduler for the disks/mpaths to noop as well. No noticeable change in performance.
We played with the max_sectors_kb and 32M doesn't seem to provide a tangible benefit either. We also tried setting nr_requests higher, same thing.
We do get about a 2x speed increase (~1.3GB/s -> ~2.5GB/s) when enabling prefetching. While better, won't this impact smaller file workloads in a negative way? Also, ~2.5GB/s is still way short of the mark. It does prove that zfs can push more bandwidth than it currently is.
We also tried tuning the zfs_vdev_[async/sync]read[max/min]_active parameters with values ranging from 1 - 256, particularly focused on zfs_vdev_async_read_max_active. These also seemingly provided no change. It seems like we're bottlenecked somewhere else.
We're also nearly set up for a test where we're going to break a LUN up into 8 smaller LUNs and then feed those into ZFS to see if it's choking on the single large block device. I don't think we really expect much out of it, but will at least give us a datapoint. I'll let you know how that goes, but in the mean time do you have any more suggestions?
Thanks!
- Jeff
The block scheduler for the disks and mpaths is "mq-deadline". This is the system default, since zfs_vdev_scheduler is disabled (at least in 2.0/master). I'm wondering if setting the scheduler to none might help.
The other oddity I found was multipath has max_sectors_kb set to 8196 for the SFA14KX (but the current versions of the multipath.conf file I've found do not have such a setting, and I believe the default is 32M instead of 8M). I'm not sure this is affecting you, given the test blocksize is 1M.
Does FIO perform better with zfs_prefetch_disable=0?
There's also a small ARC fix in ZFS 0.8.6.
memcpy seem to contribute a lot. Lustre doesn't need extra copy and can send data from ARC directly
Correct, we're running fio directly on the vdev and the results are the same for 0.8.5 and 0.7.13 (at least on this kernel version).
As far as zpool layout, each OSS is primary for two zpools, each constructed from a single block device (LUN) provided by an external storage device that handles RAID (DDN). Any other info you need, let me know.
Okay, to be clear.
You are running fio directly on a ZFS vdev and getting these result for both 0.8.5 and 0.7.13?
Can you dump info on the format of the zpool? Is it just a single logical unit on the a storage array?
A few comments here - the EDONR checksum that shows in the flame graphs seems to be consuming a lot of CPU. This checksum is new to me, so I'm not sure of its performance or overhead. Have you tried a more standard checksum (e.g. Fletcher4) which also has Intel CPU assembly optimizations that we added a few years ago?
The other question of interest is what the zpool config is like (how many disks, how many VDEVs, RAID type, etc)? Definitely ZFS gets better performance driving separate zpools than having a large single zpool, since there is otherwise contention at commit time when there are many disks in the pool. On the one hand, several 8+2 RAID-Z2 as separate OSTs will probably give better performance, but on the other hand, there is convenience and some amount of additional robustness when having at least 3 VDEVs in the pool (it allows mirror metadata copies to br written to different disks).
Finally, if you have some SSDs available and you are running ZFS 0.8+, it might be worthwhile to test with an SSD Metadata Allocation Class VDEV that is all-flash. Then ZFS could put all of the internal metadtata (dnodes, indirect blocks, Merkle tree) on the SSDs and only use the HDDs for data.