Description
Creating a new issue as a follow on for LU-14293.
This issue is affecting one production file system and one that's currently in acceptance.
When we stood up the system in acceptance, we ran some benchmarks on the raw block storage, so we're confident that the block storage can provide ~7GB/s read per LUN, with ~65GB/s read across the 12 LUNs in aggregate. What we did not do, however, was run any benchmarks on ZFS after the zpools were created on top of the LUN. Since LNET was no longer our bottleneck, we figured it would make sense to verify the stack from the bottom up, starting with the zpools. We set the zpools to `canmount=on` and changed the mountpoints, then mounted them and ran fio on them. Performance is terrible.
Given that we have another file system running with the exact same tunings and general layout, we also checked that file system in the same manner to much the same results. Since we have past benchmarking results from that file system, we're fairly confident that at some point in the past ZFS was functioning correctly. With that knowledge (and after looking at various zfs github issues) we decided to roll back from zfs 0.8.5 to 0.7.13 to test the performance there. It seems that 0.7.13 is also providing the same results.
I think that there may be potential value in rolling back our kernel to match what it was when we initialized the other file system, as there might be some odd interaction occurring with the kernel version we're running, but I'm not sure.
Here's the results of our testing on a single LUN with ZFS. Keep in mind this LUN can do ~7GB/s at the block level.
- files | read | write
1 file - 396 MB/s | 4.2 GB/s
4 files - 751 MB/s | 4.7 GB/s
12 files - 1.6 GB/s | 4.7 GB/s
And here's the really simple fio we're running to get these numbers:
fio --rw=read --size 20G --bs=1M --name=something --ioengine=libaio --runtime=60s --numjobs=12
We're also noticing some issues where Lustre is eating into those numbers significantly when layered on top. We're going to hold off on debugging that at all until zfs is stable though, as it may just be due to the same zfs issues.
Here's our current zfs module tunings:
- 'metaslab_debug_unload=1' - 'zfs_arc_max=150000000000' - 'zfs_prefetch_disable=1' - 'zfs_dirty_data_max_percent=30' - 'zfs_arc_average_blocksize=1048576' - 'zfs_max_recordsize=1048576' - 'zfs_vdev_aggregation_limit=1048576' - 'zfs_multihost_interval=10000' - 'zfs_multihost_fail_intervals=0' - 'zfs_vdev_async_write_active_min_dirty_percent=20' - 'zfs_vdev_scheduler=deadline' - 'zfs_vdev_async_write_max_active=10' - 'zfs_vdev_async_write_min_active=5' - 'zfs_vdev_async_read_max_active=16' - 'zfs_vdev_async_read_min_active=16' - 'zfetch_max_distance=67108864' - 'dbuf_cache_max_bytes=10485760000' - 'dbuf_cache_shift=3' - 'zfs_txg_timeout=60'
I've tried with zfs checksums on and off with no real change in speed. Screen grabs of the flame graphs from those runs are attached.
Attachments
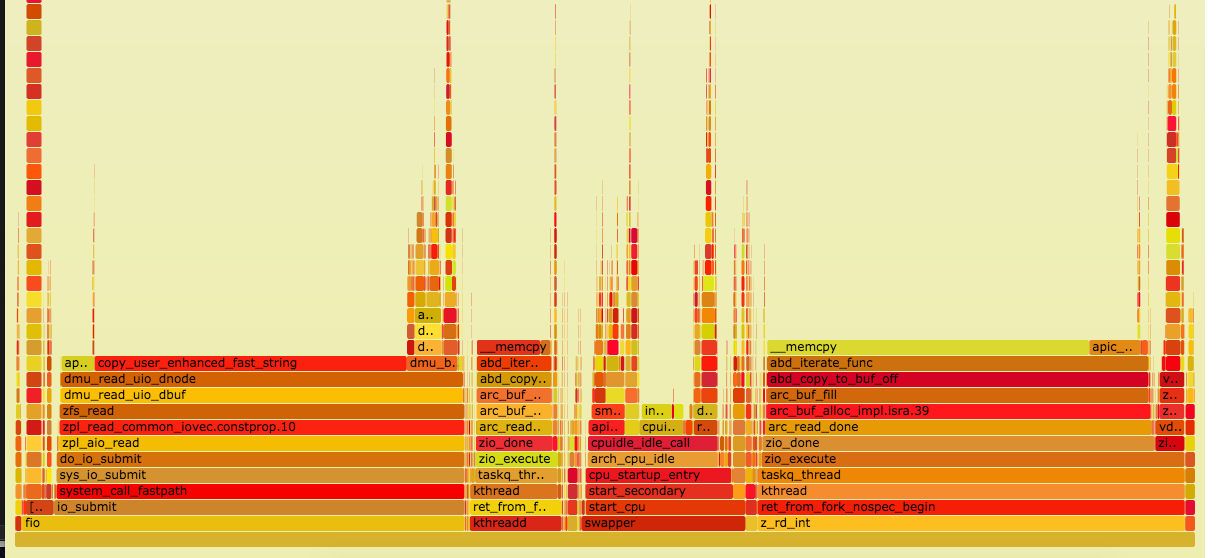
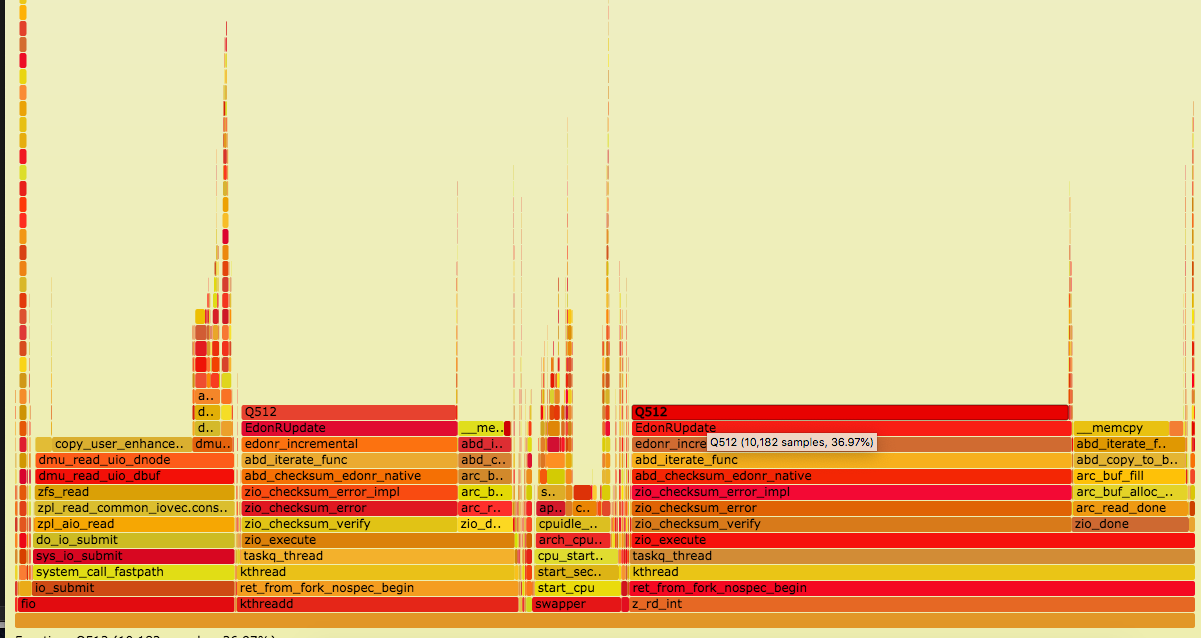
Issue Links
- is related to
-
LU-14293 Poor lnet/ksocklnd(?) performance on 2x100G bonded ethernet
-

- Resolved
-
Activity
@nilesj Out of curiosity - have you succedded with getting expected performance out of this setup?
Agree that a single VDEV zpool probably isn't the best way to organize these. I think we'll try to explore some different options there in the future. On the raid controller, yes. The backend system is a DDN 14KX with DCR pools (hence the huge LUN).
With that being said, we've recently moved to testing on a development system that has a direct attached disk enclosure and we can reproduce the problem on a scale as low as 16 disks. We tried giving ZFS full control over the disks, where we put them into a zpool with each drive as a vdev (more traditional setup) with no RAID and the results were pretty bad. We then tried to replicate the production DDN case by creating a RAID0 MD device for the exact same disks, then laid ZFS on top of that. Those results were also fairly poor. Raw mdraid device performance was as expected.
Raw mdraid device - 16 disks - 2375 MB/s write, 2850 read
mdraid with zfs on top - 16 disks - 1700 write, 950 read
zfs managing drives - 16 disks - 1500 write, 1100 read
As I mentioned on the call today, but I'll record here as well, I don't think creating the zpool on a single large VDEV is very good for ZFS performance. Preferably you should have 3 leaf VDEVs so that ditto blocks can be written to different devices. Also, a single large zpool causes contention at commit time, and in the past we saw better performance with multiple smaller zpools (e.g. 2x 8+2 RAID-Z2 VDEVs per OST) to allow better parallelism.
It sounds like you have a RAID controller in front of the disks? Is it possible that the controller is interfering with the IO from ZFS?
You don't need dnodesize=auto for the OSTs. Also, depending on what ZFS version you have, there were previously problems with this feature on the MDT.
Andreas,
The image that has 1:12 in the title shows a later run with checksumming disabled entirely, which made no meaningful change to the outcome. I am curious about your thoughts on the checksum type though, as EDONR is set on this system and our other system in the creation script. I think the reason that we're using it has been lost to time. Should we consider changing to Fletcher4, regardless of performance impact? Would be pretty low effort.
For the zpool config: Each OSS controls two zpools, each with a single VDEV created from a single ~550TB block device that's presented over IB via SRP. I believe zfs sets this up as RAID0 internally, but I'm not sure.
Unfortunately, I don't have the drives on hand to test, but I think that would make a fantastic test. Might be useful to see if it's a good idea to include SSD/NVMe in future OSS purchases to offload that VDEV onto.
Robin,
No worries on stopping by, we'll take all the help we can get. Yes, we currently set ashift to 12; recordsize on our systems is 1M to align with the block device, and dnodesize is set to auto.
I assume your enclosures are direct attached and you let ZFS handle all the disks? I think this may be part of our problem; we're trying to offload as much of this onto the block storage as possible, and ZFS just doesn't like it.
Thanks!
- Jeff
James, can you share version combination which work for you?