-
New Feature
-
Resolution: Fixed
-
 Minor
Minor
-
None
-
None
-
9223372036854775807
Now that NVIDIA has made the official release of GPUDirect Storage, we are able to release the GDS feature integration for Lustre that has been under development and testing in conjunction with NVIDIA for sometime.
This feature provides the following:
- use direct bulk IO with GPU workload
- Select the interface nearest the GPU for optimal performance
- Integrate GPU selection criteria into the LNet multi-rail selection algorithm.
- Handle IO less than 4K in a manner which works with the GPU direct workflow
- Use the memory registration/deregistration mechanism provided by the nvidia-fs driver.
Performance comparison between GPU and CPU workloads attached. Bandwidth in GB/s.

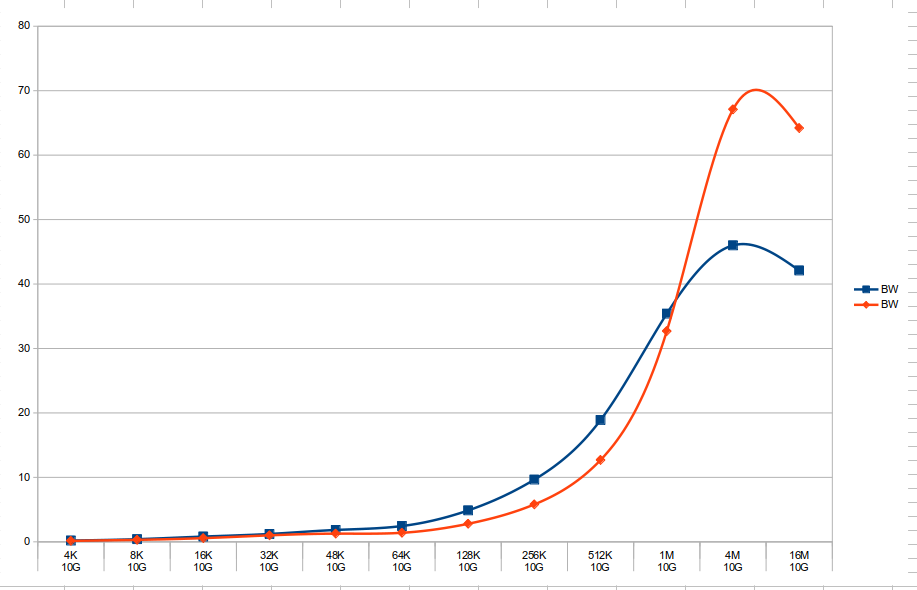
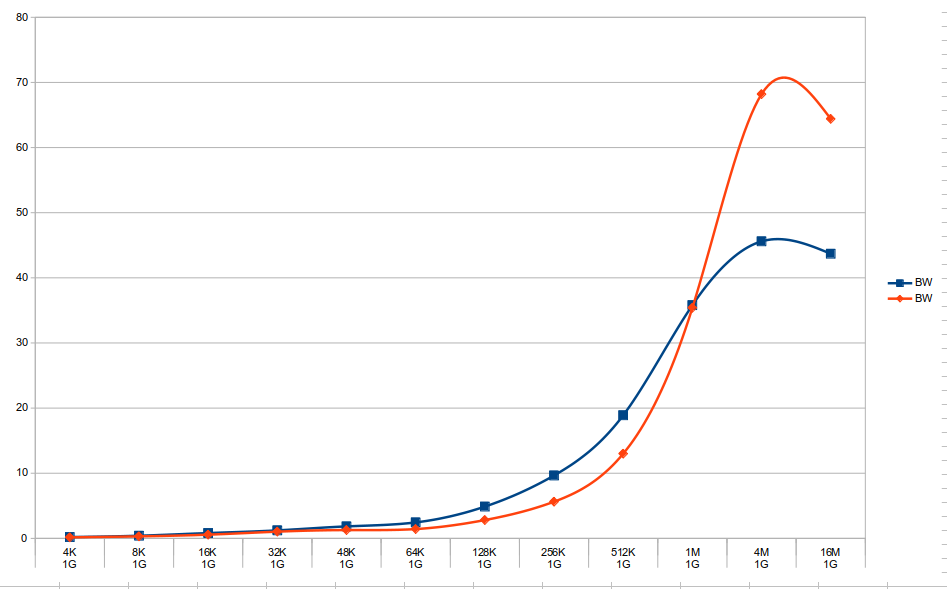
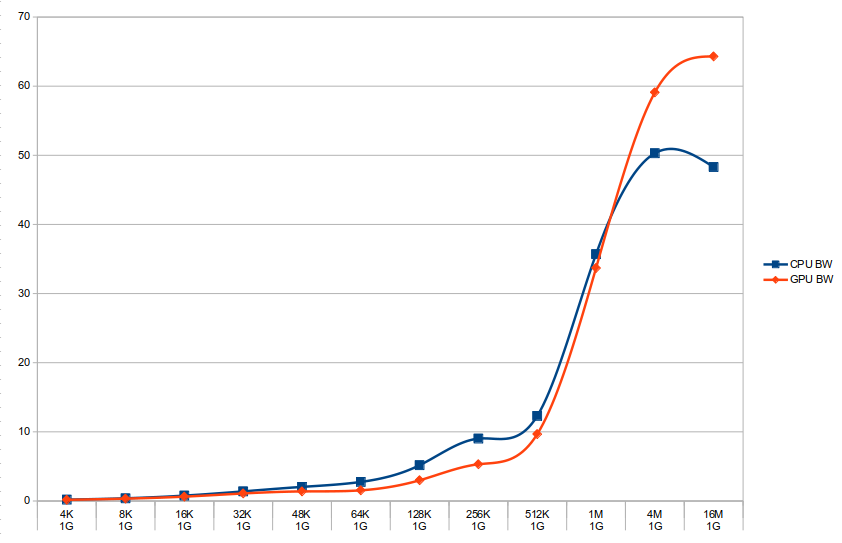
- is related to
-
-

- Closed
-