Details
-
New Feature
-
Resolution: Fixed
-
 Minor
Minor
-
None
-
None
-
9223372036854775807
Description
Now that NVIDIA has made the official release of GPUDirect Storage, we are able to release the GDS feature integration for Lustre that has been under development and testing in conjunction with NVIDIA for sometime.
This feature provides the following:
- use direct bulk IO with GPU workload
- Select the interface nearest the GPU for optimal performance
- Integrate GPU selection criteria into the LNet multi-rail selection algorithm.
- Handle IO less than 4K in a manner which works with the GPU direct workflow
- Use the memory registration/deregistration mechanism provided by the nvidia-fs driver.
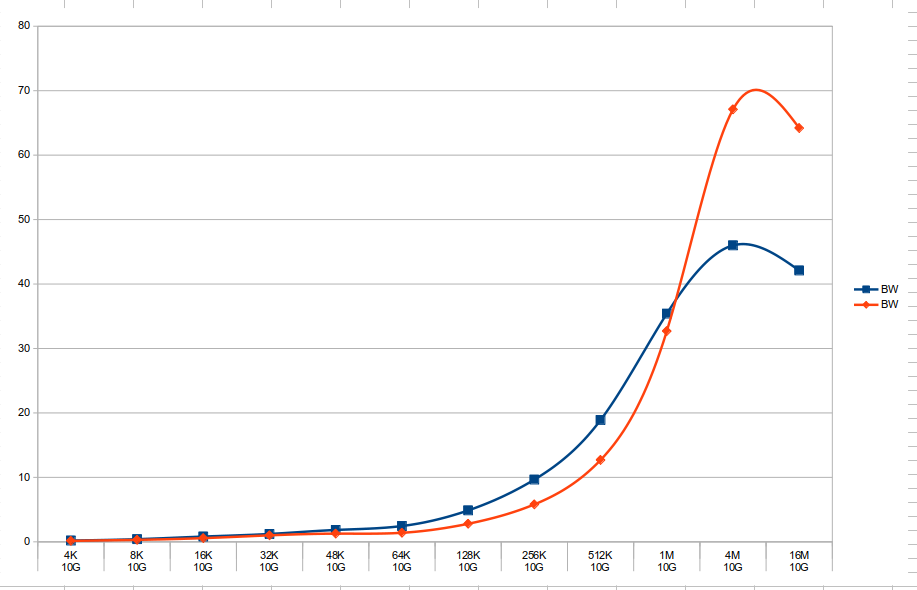
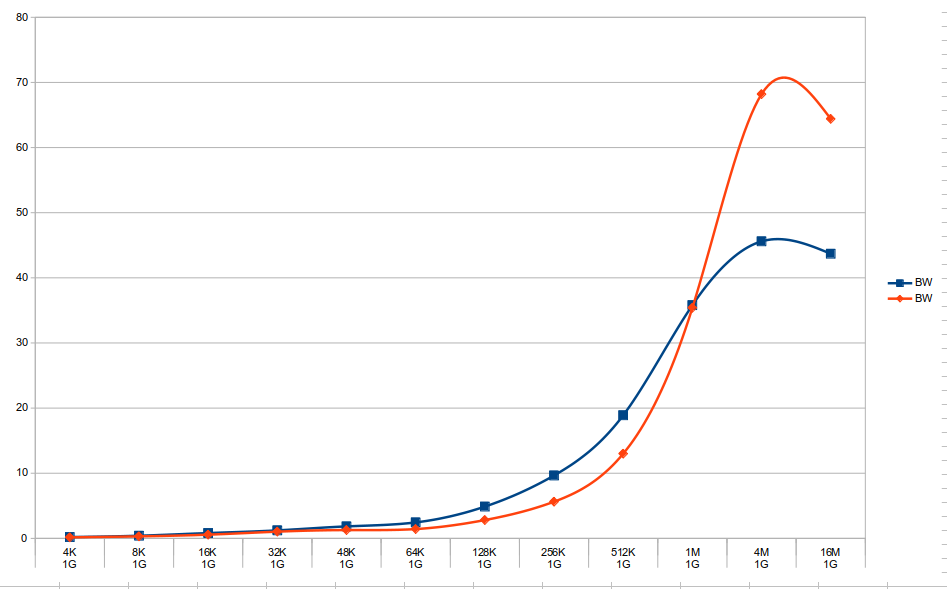
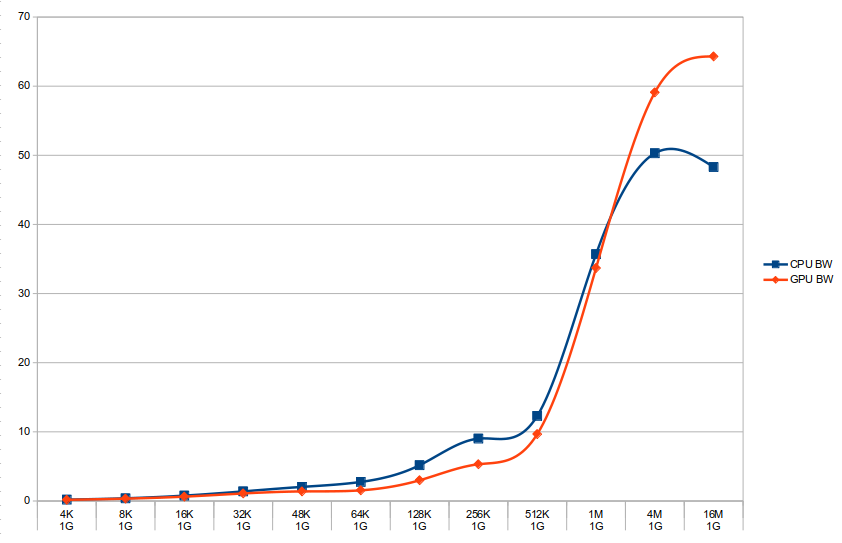
Performance comparison between GPU and CPU workloads attached. Bandwidth in GB/s.
Attachments

Issue Links
- is related to
-
-

- Closed
-
Activity
1 Gb chunk size have a less perf drop - like 5%.
+ bash llmount.sh Loading modules from /home/hpcd/alyashkov/work/lustre-wc/lustre/tests/.. detected 56 online CPUs by sysfs libcfs will create CPU partition based on online CPUs ../lnet/lnet/lnet options: 'networks=o2ib(ibs9f0) accept=all' gss/krb5 is not supported + popd /home/hpcd/alyashkov + mount -t lustre 192.168.0.210@o2ib:/hdd /lustre/hdd + lctl set_param debug=0 subsystem_debug=0 debug=0 subsystem_debug=0 + CUFILE_ENV_PATH_JSON=/home/hpcd/alyashkov/cufile.json + /usr/local/cuda-11.2/gds/tools/gdsio -f /lustre/hdd/alyashkov/foo -d 7 -w 32 -s 1G -i 1M -x 0 -I 0 -T 120 IoType: READ XferType: GPUD Threads: 32 DataSetSize: 27216896/1048576(KiB) IOSize: 1024(KiB) Throughput: 0.217678 GiB/sec, Avg_Latency: 143491.908904 usecs ops: 26579 total_time 119.240755 secs + /usr/local/cuda-11.2/gds/tools/gdsio -f /lustre/hdd/alyashkov/foo -d 0 -w 32 -s 1G -i 1M -x 0 -I 0 -T 120 IoType: READ XferType: GPUD Threads: 32 DataSetSize: 1072263168/1048576(KiB) IOSize: 1024(KiB) Throughput: 8.589992 GiB/sec, Avg_Latency: 3637.855962 usecs ops: 1047132 total_time 119.044332 secs root@ynode02:/home/hpcd/alyashkov# bash test1.sh LNET busy /home/hpcd/alyashkov/work/lustre/lustre/tests /home/hpcd/alyashkov e2label: No such file or directory while trying to open /tmp/lustre-mdt1 Couldn't find valid filesystem superblock. e2label: No such file or directory while trying to open /tmp/lustre-mdt1 Couldn't find valid filesystem superblock. e2label: No such file or directory while trying to open /tmp/lustre-ost1 Couldn't find valid filesystem superblock. Loading modules from /home/hpcd/alyashkov/work/lustre/lustre/tests/.. detected 56 online CPUs by sysfs libcfs will create CPU partition based on online CPUs ../lnet/lnet/lnet options: 'networks=o2ib(ibs9f0) accept=all' enable_experimental_features=1 gss/krb5 is not supported /home/hpcd/alyashkov debug=0 subsystem_debug=0 IoType: READ XferType: GPUD Threads: 32 DataSetSize: 27275264/1048576(KiB) IOSize: 1024(KiB) Throughput: 0.217832 GiB/sec, Avg_Latency: 143344.443230 usecs ops: 26636 total_time 119.411700 secs IoType: READ XferType: GPUD Threads: 32 DataSetSize: 1117265920/1048576(KiB) IOSize: 1024(KiB) Throughput: 8.940439 GiB/sec, Avg_Latency: 3495.253255 usecs ops: 1091080 total_time 119.178470 secs root@ynode02:/home/hpcd/alyashkov#
root@ynode02:/home/hpcd/alyashkov# bash test-wc1.sh LNET busy /home/hpcd/alyashkov/work/lustre-wc/lustre/tests /home/hpcd/alyashkov Loading modules from /home/hpcd/alyashkov/work/lustre-wc/lustre/tests/.. detected 56 online CPUs by sysfs libcfs will create CPU partition based on online CPUs ../lnet/lnet/lnet options: 'networks=o2ib(ibs9f0) accept=all' gss/krb5 is not supported /home/hpcd/alyashkov debug=0 subsystem_debug=0 IoType: READ XferType: GPUD Threads: 32 DataSetSize: 30885168/1048576(KiB) IOSize: 16(KiB) Throughput: 0.244956 GiB/sec, Avg_Latency: 1993.301007 usecs ops: 1930323 total_time 120.243414 secs IoType: READ XferType: GPUD Threads: 32 DataSetSize: 190027184/1048576(KiB) IOSize: 16(KiB) Throughput: 1.517209 GiB/sec, Avg_Latency: 321.826865 usecs ops: 11876699 total_time 119.445644 secs root@ynode02:/home/hpcd/alyashkov# bash test1-1.sh LNET busy /home/hpcd/alyashkov/work/lustre/lustre/tests /home/hpcd/alyashkov e2label: No such file or directory while trying to open /tmp/lustre-mdt1 Couldn't find valid filesystem superblock. e2label: No such file or directory while trying to open /tmp/lustre-mdt1 Couldn't find valid filesystem superblock. e2label: No such file or directory while trying to open /tmp/lustre-ost1 Couldn't find valid filesystem superblock. Loading modules from /home/hpcd/alyashkov/work/lustre/lustre/tests/.. detected 56 online CPUs by sysfs libcfs will create CPU partition based on online CPUs ../lnet/lnet/lnet options: 'networks=o2ib(ibs9f0) accept=all' enable_experimental_features=1 gss/krb5 is not supported /home/hpcd/alyashkov debug=0 subsystem_debug=0 IoType: READ XferType: GPUD Threads: 32 DataSetSize: 30880000/1048576(KiB) IOSize: 16(KiB) Throughput: 0.247379 GiB/sec, Avg_Latency: 1973.783888 usecs ops: 1930000 total_time 119.045719 secs IoType: READ XferType: GPUD Threads: 32 DataSetSize: 236412320/1048576(KiB) IOSize: 16(KiB) Throughput: 1.880670 GiB/sec, Avg_Latency: 259.630924 usecs ops: 14775770 total_time 119.883004 secs
IO load generated by
/usr/local/cuda-11.2/gds/tools/gdsio -f /lustre/hdd/alyashkov/foo -d 7 -w 32 -s 1G -i 16k -x 0 -I 0 -T 120
/usr/local/cuda-11.2/gds/tools/gdsio -f /lustre/hdd/alyashkov/foo -d 0 -w 32 -s 1G -i 16k -x 0 -I 0 -T 120
Host is HP Proliant -> 8 GPU + 2 IB cards. GPU in the two NUMA nodes - GPU0 .. GPU3 in NUMA0, GPU4 - 7 in NUMA1. IB0 (active) NUMA0, IB1 (inactive) NUMA1. Connected to the L300 system. 1 stripe per file.
OS Ubuntu 20.04 + 5.4 kernel + MOFED 5.3.
nvidia-fs from the GDS 1.0 release.
This difference likely because lnet_select_best_ni differences and expected for the WC patch version.
Can you share more details of the tests so someone can try to reproduce?
I run smoke performance testing. my results is WC implementation in 5% slow than Cray for 1G steam IO and 23% slow for 16k IO.
Oleg Drokin (green@whamcloud.com) merged in patch https://review.whamcloud.com/44109/
Subject: LU-14798 lnet: RMDA infrastructure updates
Project: fs/lustre-release
Branch: master
Current Patch Set:
Commit: 7ac839837c1c6cd1ff629c7898349db8cc55891d
Sure, that is great. But unless NVIDIA accepts your changes and ships then out, everyone other than you will be using their version of the nvidia-fs.ko module that needs these Lustre changes to work.
i confused. I spent a two weeks to add 200 LOC patch into gdrcopy to have a DIO + zero copy with GPU.
But I can't publish it because it want to change a gdrcopy license. It have now an MIT but this implementation want to be GPL-ed.
That implementation don't needs to have change a GDS interface for CUDA programs just to rewrite a some parts inside of nvidia-fs module.
Main problem - nvidia driver isn't register an PCIe memory as system resource. One this memory will be registered and "struct page exist" - it's easy to export it to use with userspace. Like dma_buf API.
And it have nothing for lustre changes.
Sure, I believe that this is possible to change in the future. However, NVIDIA just spent more than a year developing and testing GDS in the current form before releasing it, so they are not going to change it quickly because we ask them. There are many other companies involved using GDS, so they would all have to change their interface as well. I think it is more likely that this may be changed in a year or two in a "GDS 2.0" release. In the meantime, I think we have to accept that GDS works the way it does today, and if/when it changes in the future we would update to match that interface when it becomes available.
@James,
Can you ask an NVidia guys - is they ready to "fix" an nvida driver to register GPU memory as system memory (it's part of DMA bufs or p2p DMA process). It they can add this into driver (it's easy - like 100-200 LOC - i can share a code example). This will avoid requirements to patch a lustre. As current problem is "NVidia don't register a PCI-e device memory as sytem one, it mean this memory can't be subject of DIO".
Performance questions can be solved in generic way via PCIe distance handling.
@Andeas,
can you trust me, if i say - GDS can work without any lustre patches? but it's true. I'm not clear about legal part of it - but this is possible from technical view. Current nvidia-fs module have a clean IOCTL API + nv_peer module for the MOFED <> GPU connection.
@Andreas. You are correct in that we use the Cray GNI LND driver which has support behind it from Cray so if we do have issues we can work with engineers to resolve problems. ORNL tends to be more conservative in what it deploys due to the fact at our scales we see problems others don't. ORNL can consider GDS when we have fully tested it at scale and can work in partnership with NVIDIA engineers to resolve any at scale bugs. MOFED is the same way. In fact we have had the Mellanox engineers on site before. I was just answering Patrick his question about our own hesitation to deployment this new feature.
I'm not standing in the way of landing this work. I understand as an organization your focus is Lustre and what is today. ORNL is looking to expand into all areas in the Linux kernel that is HPC related for forward facing work. I do have the flexibility to rework the GDS driver and submit changes. I also can approach the DRM / TTM guys to create GDS like work on other platforms besides NVIDIA. I'm thinking of the longer term road map to that is good for everyone. For example we would like to be able to use something like GDS for SRP as well. That is not of much interest to Lustre but it is to us.
results after 10 iterations.
[alyashkov@hpcgate ~]$ for i in `ls log-*16k`; do echo $i; grep "Throughput: 1." $i | awk '{if ($10 == "16(KiB)") {sum += $12;}} END { print sum/10;}'; done log-cray-16k 1.84928 log-master-16k 1.87858 log-wc-16k 1.54516 [alyashkov@hpcgate ~]$ for i in `ls log-*16k`; do echo $i; grep "Throughput: 0." $i | awk '{if ($10 == "16(KiB)") {sum += $12;}} END { print sum/10;}'; done log-cray-16k 0.247549 log-master-16k 0.247369 log-wc-16k 0.245084test script is same for each tree except a directory to module load.
test system -HPe ProLiant XL270d Gen9
PCIe tree
root@ynode02:/home/hpcd/alyashkov# lspci -tv -+-[0000:ff]-+-08.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 0 | +-08.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 0 | +-09.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 1 | +-09.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 1 | +-0b.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link 0/1 | +-0b.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link 0/1 | +-0b.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link 0/1 | +-0b.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link Debug | +-0c.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-10.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R2PCIe Agent | +-10.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R2PCIe Agent | +-10.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Ubox | +-10.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Ubox | +-10.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Ubox | +-12.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 0 | +-12.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 0 | +-12.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 0 Debug | +-12.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 1 | +-12.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 1 | +-12.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 1 Debug | +-13.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Target Address/Thermal/RAS | +-13.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Target Address/Thermal/RAS | +-13.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel Target Address Decoder | +-13.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel Target Address Decoder | +-13.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Broadcast | +-13.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Global Broadcast | +-14.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 0 Thermal Control | +-14.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 1 Thermal Control | +-14.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 0 Error | +-14.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 1 Error | +-14.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-14.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-14.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-14.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-16.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Target Address/Thermal/RAS | +-16.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Target Address/Thermal/RAS | +-16.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Channel Target Address Decoder | +-16.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Channel Target Address Decoder | +-16.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Broadcast | +-16.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Global Broadcast | +-17.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 0 Thermal Control | +-17.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 1 Thermal Control | +-17.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 0 Error | +-17.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 1 Error | +-17.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-17.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-17.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-17.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-1e.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1f.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | \-1f.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit +-[0000:80]-+-00.0-[94]-- | +-01.0-[95]-- | +-01.1-[96]-- | +-02.0-[81-8b]----00.0-[82-8b]--+-04.0-[83]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] | | +-08.0-[86]-- | | \-0c.0-[89]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] | +-02.1-[97]-- | +-02.2-[98]-- | +-02.3-[99]-- | +-03.0-[8c-93]----00.0-[8d-93]--+-08.0-[8e]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] | | \-10.0-[91]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] | +-03.1-[9a]-- | +-03.2-[9b]-- | +-03.3-[9c]-- | +-04.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 0 | +-04.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 1 | +-04.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 2 | +-04.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 3 | +-04.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 4 | +-04.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 5 | +-04.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 6 | +-04.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 7 | +-05.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Map/VTd_Misc/System Management | +-05.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D IIO Hot Plug | +-05.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D IIO RAS/Control Status/Global Errors | \-05.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D I/O APIC +-[0000:7f]-+-08.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 0 | +-08.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 0 | +-09.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 1 | +-09.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D QPI Link 1 | +-0b.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link 0/1 | +-0b.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link 0/1 | +-0b.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link 0/1 | +-0b.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R3 QPI Link Debug | +-0c.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0c.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0d.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-0f.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Caching Agent | +-10.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R2PCIe Agent | +-10.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D R2PCIe Agent | +-10.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Ubox | +-10.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Ubox | +-10.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Ubox | +-12.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 0 | +-12.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 0 | +-12.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 0 Debug | +-12.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 1 | +-12.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 1 | +-12.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Home Agent 1 Debug | +-13.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Target Address/Thermal/RAS | +-13.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Target Address/Thermal/RAS | +-13.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel Target Address Decoder | +-13.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel Target Address Decoder | +-13.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Broadcast | +-13.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Global Broadcast | +-14.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 0 Thermal Control | +-14.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 1 Thermal Control | +-14.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 0 Error | +-14.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 0 - Channel 1 Error | +-14.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-14.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-14.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-14.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 0/1 Interface | +-16.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Target Address/Thermal/RAS | +-16.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Target Address/Thermal/RAS | +-16.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Channel Target Address Decoder | +-16.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Channel Target Address Decoder | +-16.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Broadcast | +-16.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Global Broadcast | +-17.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 0 Thermal Control | +-17.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 1 Thermal Control | +-17.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 0 Error | +-17.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Memory Controller 1 - Channel 1 Error | +-17.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-17.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-17.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-17.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DDRIO Channel 2/3 Interface | +-1e.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1e.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | +-1f.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit | \-1f.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Power Control Unit \-[0000:00]-+-00.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D DMI2 +-01.0-[16]-- +-01.1-[1c]-- +-02.0-[03-0a]----00.0-[04-0a]--+-08.0-[05]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] | \-10.0-[08]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] +-02.1-[1d]-- +-02.2-[1e]-- +-02.3-[1f]-- +-03.0-[0b-15]----00.0-[0c-15]--+-04.0-[0d]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] | +-08.0-[10]--+-00.0 Mellanox Technologies MT27700 Family [ConnectX-4] | | \-00.1 Mellanox Technologies MT27700 Family [ConnectX-4] | \-0c.0-[13]----00.0 NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] +-03.1-[19]-- +-03.2-[1a]-- +-03.3-[1b]-- +-04.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 0 +-04.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 1 +-04.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 2 +-04.3 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 3 +-04.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 4 +-04.5 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 5 +-04.6 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 6 +-04.7 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Crystal Beach DMA Channel 7 +-05.0 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D Map/VTd_Misc/System Management +-05.1 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D IIO Hot Plug +-05.2 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D IIO RAS/Control Status/Global Errors +-05.4 Intel Corporation Xeon E7 v4/Xeon E5 v4/Xeon E3 v4/Xeon D I/O APIC +-11.0 Intel Corporation C610/X99 series chipset SPSR +-14.0 Intel Corporation C610/X99 series chipset USB xHCI Host Controller +-1a.0 Intel Corporation C610/X99 series chipset USB Enhanced Host Controller #2 +-1c.0-[20]-- +-1c.2-[01]--+-00.0 Hewlett-Packard Company Integrated Lights-Out Standard Slave Instrumentation & System Support | +-00.1 Matrox Electronics Systems Ltd. MGA G200EH | +-00.2 Hewlett-Packard Company Integrated Lights-Out Standard Management Processor Support and Messaging | \-00.4 Hewlett-Packard Company Integrated Lights-Out Standard Virtual USB Controller +-1c.4-[02]--+-00.0 Intel Corporation I350 Gigabit Network Connection | \-00.1 Intel Corporation I350 Gigabit Network Connection +-1d.0 Intel Corporation C610/X99 series chipset USB Enhanced Host Controller #1 +-1f.0 Intel Corporation C610/X99 series chipset LPC Controller +-1f.2 Intel Corporation C610/X99 series chipset 6-Port SATA Controller [AHCI mode] \-1f.3 Intel Corporation C610/X99 series chipset SMBus ControllerMLNX_OFED_LINUX-5.3-1.0.0.1 (OFED-5.3-1.0.0):
/usr/src/nvidia-460.80 /usr/src/nvidia-fs-2.3.4 /usr/src/nvidia-fs-2.7.49