-
 Epic
Epic
-
Resolution: Unresolved
-
 Major
Major
-
None
-
Lustre 2.2.0
-
None
-
See below.
-
4044
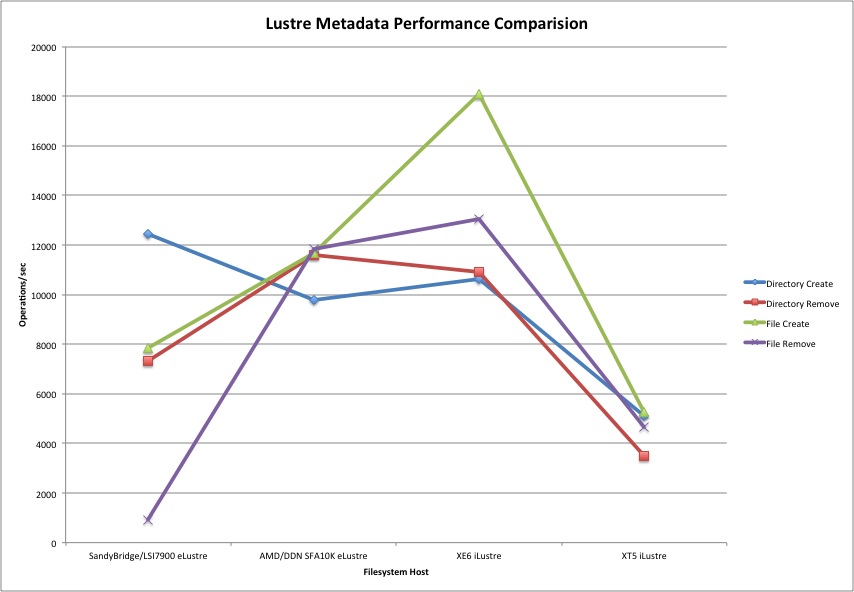
Over the past 12 months we at CSCS have been carefully benchmarking the Lustre metadata performance from the compute nodes of our Cray XE6 system. In this timeframe we have had four distinct configurations of the scratch filesystem namely:
a) Cray XE6 (Gemini interconnect) connected via 12 QDR IB connections from 12 Service Nodes acting as routers to the Compute Nodes and a QDR switch to an external Lustre v2.2 filesystem hosted by 12 Intel SandyBridge OSSes (Intel Xeon CPU E5-2670 2.60GHz 64GByte RAM, dual socket 16 cores/socket running in hyperthreaded mode) and 2 AMD Opteron MDSes (AMD Opteron 6128 64GBytes RAM, 2.0 GHz, dual socket 8 cores/socket) and with 6 LSI7900 controller couplets and 768 10K rpm 2TB SATA drives in 48 enclosures formatted as 72 8+2PQ RAID6 LUNs and connected to the servers via 12 8Gbit/sec FC connections;
b) Cray XE6 (Gemini interconnect) connected via 4 QDR IB connections from 4 Service Nodes acting as routers to the Compute Nodes and a QDR switch to an external Lustre v1.8.4 filesystem hosted by 4 AMD Opteron OSSes (AMD Opteron 6134 2.3 GHz 32 GBytes RAM, dual socket 8 cores/socket) and 2 AMD Opteron MDSes (AMD Opteron 2218 dual socket 2 cores/socket) and with on DDN SFA10K controller couplet and 290 7200rpm 1863GByte SATA drives in 5 SA4601 enclosures;
c) Cray XE6 (Gemini interconnect) hosting an internal Lustre v1.8.4 filesystem via 12 Service Nodes acting as OSSes (AMD Opteron, 2.2 GHz, single socket 6cores/socket) and 1 Service Node acting as MDS (spec same as OSSes) and with the same back-end storage hardware as in a) above direct attached via 8Gbit/sec FC;
d) Cray XT5 (SeaStar interconnect) hosting an internal Lustre v1.6.3 filesystem via 20 Service Nodes acting as OSSes (AMD Opteron, 2.6 GHz, single socket, dual Core, 8 GBytes RAM) and 1 service node acting as MDS (spec same as the OSSes) and with 5 LSI7900 controller couplets and 800 512GB 7200rpm SATA drives in 50 enclosures formatted as 80 8+2PQ RAID6 LUNs and connected to the OSSes via 4Gbit/sec FC.
We used the mdtest application to gather the following results (in operations/second) for each of the above described filesystems. There were 1,400 clients spread over 175, 88 and 44 nodes. The tests were repeated multiple times in each case and the best numbers are presented (I've also attached a graph of the results).
Directory create:
(a) 12457.32
(b) 9797.77
(c) 10610.32
(d) 5113.98
Directory remove:
(a) 7342.54
(b) 11586.95
(c) 10906.81
(d) 3504.84
File create:
(a) 7842.85
(b) 11685.58
(c) 18069.77
(d) 5255.05
File remove:
(a) 932.045
(b) 11836.41
(c) 13043.88
(d) 4644.71
As can be seen from the results the latest filesystem based on Lustre v2.2 with Intel SandyBridge OSSes and AMD Opteron MDSes has almost the worst performance, except in the case of directory create where it is marginally better than the internal Lustre v1.8.4 filesystem. It was our expectation that the new v2.2 Lustre filesystem would perform, in all cases, at least as well as the old v1.8.4 internal filesystem(config c) above). Can WhamCloud please offer advice and tuning options to improve the performance of the Lustre v2.2 filesystem.