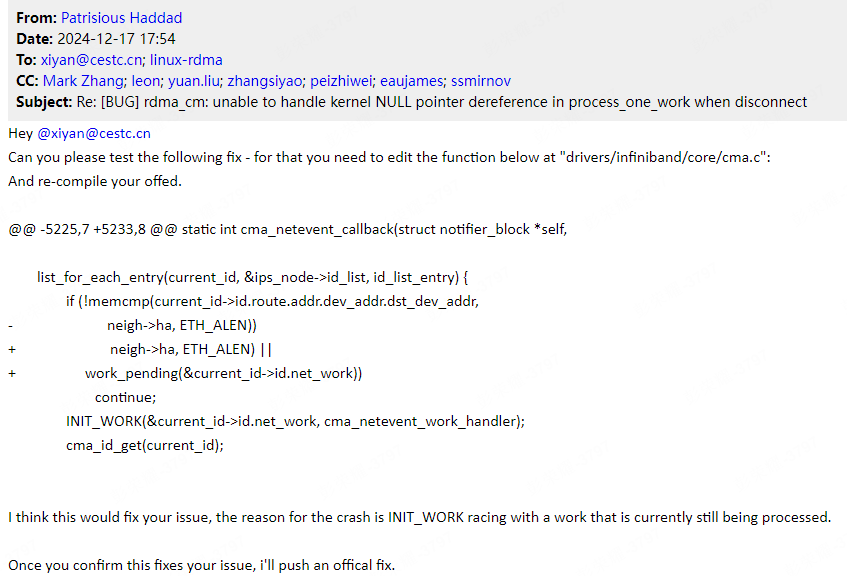
-
Bug
-
Resolution: Unresolved
-
 Minor
Minor
-
None
-
Lustre 2.15.5
-
Lustre server 2.15.5 RoCE
Lustre MGS 2.15.5 RoCE
Lustre client 2.15.5 RoCE
-
3
-
9223372036854775807
- Lustre's client and server are deployed within the VM, The VM uses the network card PF pass-through mode.
【OS】
VM Version: qemu-kvm-7.0.0
OS Verion: Rocky 8.10
Kernel Verion: 4.18.0-553.el8_10.x86_64
【Network Card】
Client:
MLX CX6 1*100G RoCE v2
MLNX_OFED_LINUX-23.10-3.2.2.0-rhel8.10-x86_64
Server:
MLX CX6 2*100G RoCE v2 bond
MLNX_OFED_LINUX-23.10-3.2.2.0-rhel8.10-x86_64
【BUG Info】
Here is the following reproducer:
- Mount lustre on a RoCE network
- Construct Luster server reboot
- Crash occurs on the server
Server call trace:
crash> bt
PID: 144 TASK: ff1f28f603dcc000 CPU: 4 COMMAND: "kworker/u40:12"
#0 [ff310f004368bbc0] machine_kexec at ffffffffadc6f353
#1 [ff310f004368bc18] __crash_kexec at ffffffffaddbaa7a
#2 [ff310f004368bcd8] crash_kexec at ffffffffaddbb9b1
#3 [ff310f004368bcf0] oops_end at ffffffffadc2d831
#4 [ff310f004368bd10] no_context at ffffffffadc81cf3
#5 [ff310f004368bd68] __bad_area_nosemaphore at ffffffffadc8206c
#6 [ff310f004368bdb0] do_page_fault at ffffffffadc82cf7
#7 [ff310f004368bde0] page_fault at ffffffffae8011ae
[exception RIP: process_one_work+46]
RIP: ffffffffadd1943e RSP: ff310f004368be98 RFLAGS: 00010046
RAX: 0000000000000000 RBX: ff1f28f60a7575d8 RCX: ff1f28f6aab70760
RDX: 00000000fffeae01 RSI: ff1f28f60a7575d8 RDI: ff1f28f603dca840
RBP: ff1f28f600019400 R8: 00000000000000ad R9: ff310f004368bb88
R10: ff310f004368bd68 R11: ff1f28f6cb1550ac R12: 0000000000000000
R13: ff1f28f600019420 R14: ff1f28f6000194d0 R15: ff1f28f603dca840
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#8 [ff310f004368bed8] worker_thread at ffffffffadd197d0
#9 [ff310f004368bf10] kthread at ffffffffadd20e24
#10 [ff310f004368bf50] ret_from_fork at ffffffffae80028f
Server kernel log:
[ 50.700202] Lustre: Lustre: Build Version: 2.15.5
[ 50.717961] LNet: Using FastReg for registration
[ 50.876539] LNet: Added LNI 10.255.40.5@o2ib [8/256/0/180]
[ 50.974248] LDISKFS-fs (nvme0n1): mounted filesystem with ordered data mode. Opts: user_xattr,errors=remount-ro,no_mbcache,nodelalloc
[ 52.201495] LDISKFS-fs (nvme0n2): mounted filesystem with ordered data mode. Opts: errors=remount-ro,no_mbcache,nodelalloc
.............................................
[ 105.395060] Lustre: lustre-OST000c: deleting orphan objects from 0x400000402:1506 to 0x400000402:1569
[ 105.396348] Lustre: lustre-OST0003: deleting orphan objects from 0x340000401:6 to 0x340000401:1793
[ 105.396611] Lustre: lustre-OST000c: deleting orphan objects from 0x0:3000 to 0x0:3041
................................................
[ 162.093229] LustreError: 137-5: lustre-OST0007_UUID: not available for connect from 10.255.102.59@o2ib (no target). If you are running an HA pair check that the target is mounted on the other server.
[ 162.093412] LustreError: Skipped 3 previous similar messages
[ 162.276036] hrtimer: interrupt took 5325 ns
[ 162.320673] LDISKFS-fs warning (device nvme0n14): ldiskfs_multi_mount_protect:331: MMP interval 42 higher than expected, please wait.
[ 183.775739] LDISKFS-fs warning (device nvme0n14): ldiskfs_multi_mount_protect:344: Device is already active on another node.
[ 183.775759] LDISKFS-fs warning (device nvme0n14): ldiskfs_multi_mount_protect:344: MMP failure info: last update time: 1728560802, last update node: node2-lustre, last update device: nvme0n14
[ 183.775924] LustreError: 7105:0:(osd_handler.c:8111:osd_mount()) lustre-OST000d-osd: can't mount /dev/nvme0n14: -22
[ 183.776234] LustreError: 7105:0:(obd_config.c:774:class_setup()) setup lustre-OST000d-osd failed (-22)
[ 183.776330] LustreError: 7105:0:(obd_mount.c:200:lustre_start_simple()) lustre-OST000d-osd setup error -22
[ 183.776495] LustreError: 7105:0:(obd_mount_server.c:1993:server_fill_super()) Unable to start osd on /dev/nvme0n14: -22
[ 183.776600] LustreError: 7105:0:(super25.c:183:lustre_fill_super()) llite: Unable to mount <unknown>: rc = -22
[ 184.223017] LDISKFS-fs (nvme0n14): mounted filesystem with ordered data mode. Opts: errors=remount-ro,no_mbcache,nodelalloc
[ 184.354454] Lustre: lustre-OST000d: Imperative Recovery not enabled, recovery window 300-900
[ 184.354461] Lustre: Skipped 5 previous similar messages
[ 186.335038] Lustre: 4064:0:(client.c:2295:ptlrpc_expire_one_request()) @@@ Request sent has timed out for sent delay: [sent 1728560819/real 0] req@00000000c5c19397 x1812527255153280/t0(0) o400->lustre-MDT0002-lwp-OST000c@10.255.40.6@o2ib:12/10 lens 224/224 e 0 to 1 dl 1728560826 ref 2 fl Rpc:XNr/0/ffffffff rc 0/-1 job:''
[ 186.335045] Lustre: 4064:0:(client.c:2295:ptlrpc_expire_one_request()) Skipped 1 previous similar message
[ 186.335049] Lustre: lustre-MDT0000-lwp-OST000c: Connection to lustre-MDT0000 (at 10.255.40.6@o2ib) was lost; in progress operations using this service will wait for recovery to complete
[ 191.279301] Lustre: lustre-OST000d: Will be in recovery for at least 5:00, or until 4 clients reconnect
[ 191.279307] Lustre: Skipped 4 previous similar messages
[ 203.233227] Lustre: lustre-MDT0000-lwp-OST000c: Connection restored to 10.255.40.7@o2ib (at 10.255.40.7@o2ib)
[ 208.086625] LustreError: 137-5: lustre-MDT0000_UUID: not available for connect from 10.255.40.7@o2ib (no target). If you are running an HA pair check that the target is mounted on the other server.
[ 208.086693] Lustre: lustre-OST000d: Denying connection for new client lustre-MDT0002-mdtlov_UUID (at 10.255.40.7@o2ib), waiting for 4 known clients (3 recovered, 0 in progress, and 0 evicted) to recover in 4:42
[ 208.107410] Lustre: lustre-OST000d: Recovery over after 0:17, of 4 clients 4 recovered and 0 were evicted.
[ 208.107414] Lustre: Skipped 4 previous similar messages
[ 208.109912] Lustre: lustre-OST000d: deleting orphan objects from 0x580000402:2050 to 0x580000402:2081
[ 208.110745] Lustre: lustre-OST000d: deleting orphan objects from 0x580000401:8 to 0x580000401:2017
[ 208.353096] Lustre: lustre-MDT0000-lwp-OST0009: Connection restored to 10.255.40.7@o2ib (at 10.255.40.7@o2ib)
[ 208.353099] Lustre: Skipped 1 previous similar message
[ 208.945247] Lustre: lustre-OST0000: deleting orphan objects from 0x0:3128 to 0x0:3201
.........................................................................................
[ 213.409120] Lustre: lustre-MDT0000-lwp-OST0006: Connection restored to 10.255.40.7@o2ib (at 10.255.40.7@o2ib)
[ 213.409125] Lustre: Skipped 7 previous similar messages
[ 213.472526] BUG: unable to handle kernel NULL pointer dereference at 0000000000000008