Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
Lustre 2.4.0
-
None
-
Hyperion/LLNL
-
3
-
8187
Description
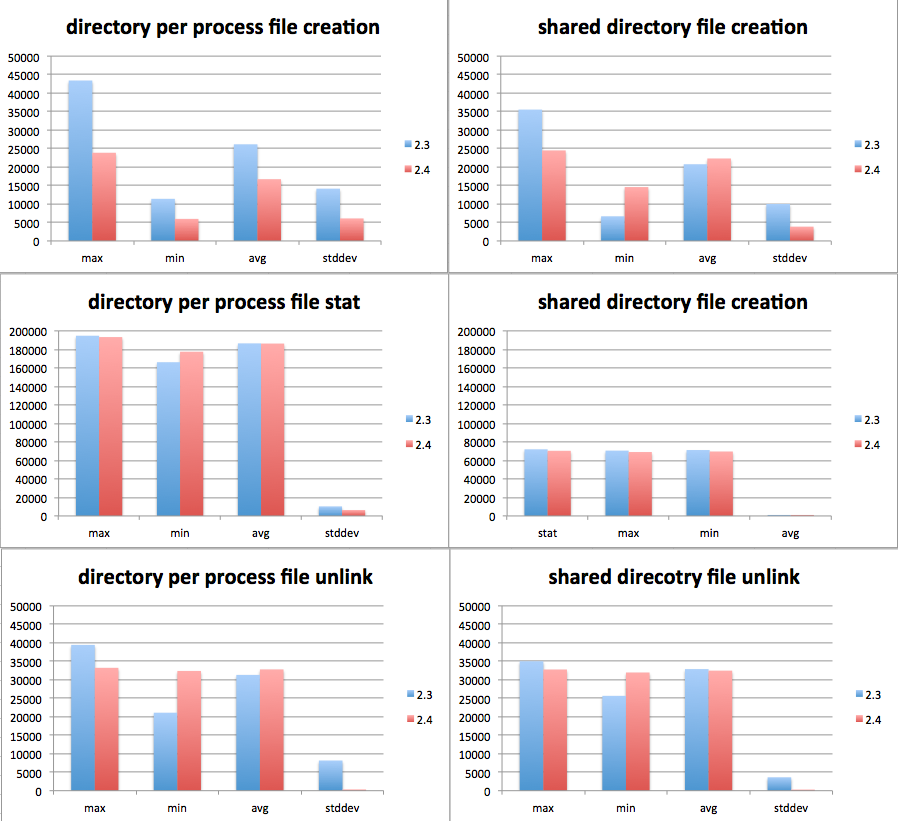
We performed a comparison between 2.3.0, 2.1.5 and current Lustre. We say a regression in metadata performance compared to 2.3.0. Spreadsheet attached.
Attachments
Issue Links
- is blocked by
-
-
- Closed
-
Activity
James, please submit the SLES changes as a separate patch. Since this doesn't affect the API, the two changes do not need to be in the same commit. If the other patch needs to be refreshed for some other reason they can be merged.
This patch will need to be port to SLES11 SP[1/2] as well. Later in the week I can include it in the patch.
Niu's patch is at http://review.whamcloud.com/6440.
Minh, would you be able to run another set of tests with the latest patch applied, and produce a graph like:
https://jira.hpdd.intel.com/secure/attachment/12415/mdtest_create.png
so it is easier to see what the differences are? Presumably with 5 runs it would be useful to plot the standard deviation, since I see from the text results you posted above that the performance can vary dramatically between runs.
Instead of eliminate the global locks entirely, maybe a small fix in dquot_initialize() could relieve the contenion caused by dqget()/dqput(): In dquot_initialize(), we'd call dqget() only when i_dquot not initialized, which can avoid 2 pair of dqget()/dqput() in most case. I'll propose a patch soon.
dqget()/dqput() is mainly to get/drop reference on the in-memory per-id data of dquot, and it acquires global locks like lock dq_list_lock & dq_state_lock, (since it will lookup the dquot list and do some state checking) so contention on those global locks could be severe in the test case. If we can replace them with RCU or read/write lock, things will be better.
I heard from Lai that there were some old patches which tried to remove those global locks, but it didn't gain much interest of community and not reviewed. Lai, could you comment on this?
Regarding the quota record commit (mark_dquot_dirty() -> ext4_mark_dquot_dirty() -> ext4_write_dquot() -> dquot_commit(), which should happen along with each transaction), it does require global locks: dqio_mutex & dq_list_lock, but surprisingly, I didn't see it in the top samples of oprofile, it might just because the dqget()/dqput() calls are much more than dquot commit calls? Once we resolved the bottleneck in dqget()/dqput(), the contention in dquot commit could probably come to light.
I find it strange that dqget() is called 2M times, but it only looks like 20k blocks are being allocated (based on the ldiskfs an jbd2 call counts). Before trying to optimize the speed of that function, it is probably better to reduce the number of times it is called?
It is also a case where the same quota entry is being accessed for every call (same UID and GID each time), so I wonder if that common case could be optimized in some way?
Are any of these issues fixed in the original quota patches?
Unfortunately, since all of the threads are contending to update the same record, there isn't an easy way to reduce contention. The only thing I can think of is to have a journal pre-commit callback that does only a single quota update to disk per transaction, and uses percpu counters for the per-quota-per-transaction updates in memory. That would certainly avoid contention, and is no less correct in the face of a crash. No idea how easy that would be to implement.
Look closer into the dqget()/dqput(), I realized that there is still quite a few global locks in quota code: dq_list_lock, dq_state_lock, dq_data_lock. The fix of LU-2442 only removes the global lock of dqptr_sem, which has the most significant impact on performace. Removing all of the quota global locks requires lots of changes in VFS code, that isn't a small project, maybe we should open a new project for further release?
From Minh's result we can see: because of quota file updating, when testing 256 threads over 256 directories (1 thread per directory, no contention on parent directory updating), create/unlink of w/o quota is faster than create/unlink with quota on. I think the oprofile data confirms it:
Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000 samples % image name app name symbol name 2276160 46.2251 vmlinux vmlinux dqput 963873 19.5747 vmlinux vmlinux dqget 335277 6.8089 ldiskfs ldiskfs /ldiskfs 258028 5.2401 vmlinux vmlinux dquot_mark_dquot_dirty 110819 2.2506 osd_ldiskfs osd_ldiskfs /osd_ldiskfs 76925 1.5622 obdclass obdclass /obdclass 58193 1.1818 mdd mdd /mdd 41931 0.8516 vmlinux vmlinux __find_get_block 32408 0.6582 lod lod /lod 20711 0.4206 jbd2.ko jbd2.ko jbd2_journal_add_journal_head 18598 0.3777 jbd2.ko jbd2.ko do_get_write_access 18579 0.3773 vmlinux vmlinux __find_get_block_slow 18364 0.3729 libcfs libcfs /libcfs 17833 0.3622 oprofiled oprofiled /usr/bin/oprofiled 17472 0.3548 vmlinux vmlinux mutex_lock
I'm not sure if we can still improve the performance (with quota) further in this respect, because single quota file updating can always be the bottleneck.
performance data for the patch