-
Bug
-
Resolution: Cannot Reproduce
-
 Minor
Minor
-
None
-
Lustre 2.4.0
-
None
-
3
-
9680
Hi,
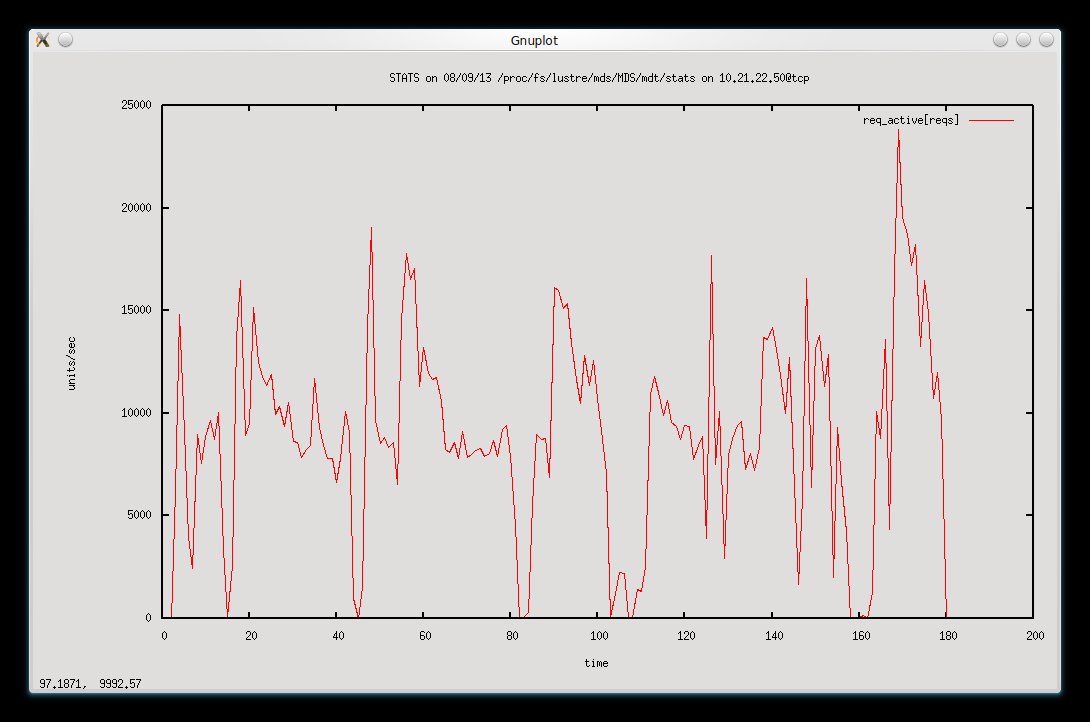
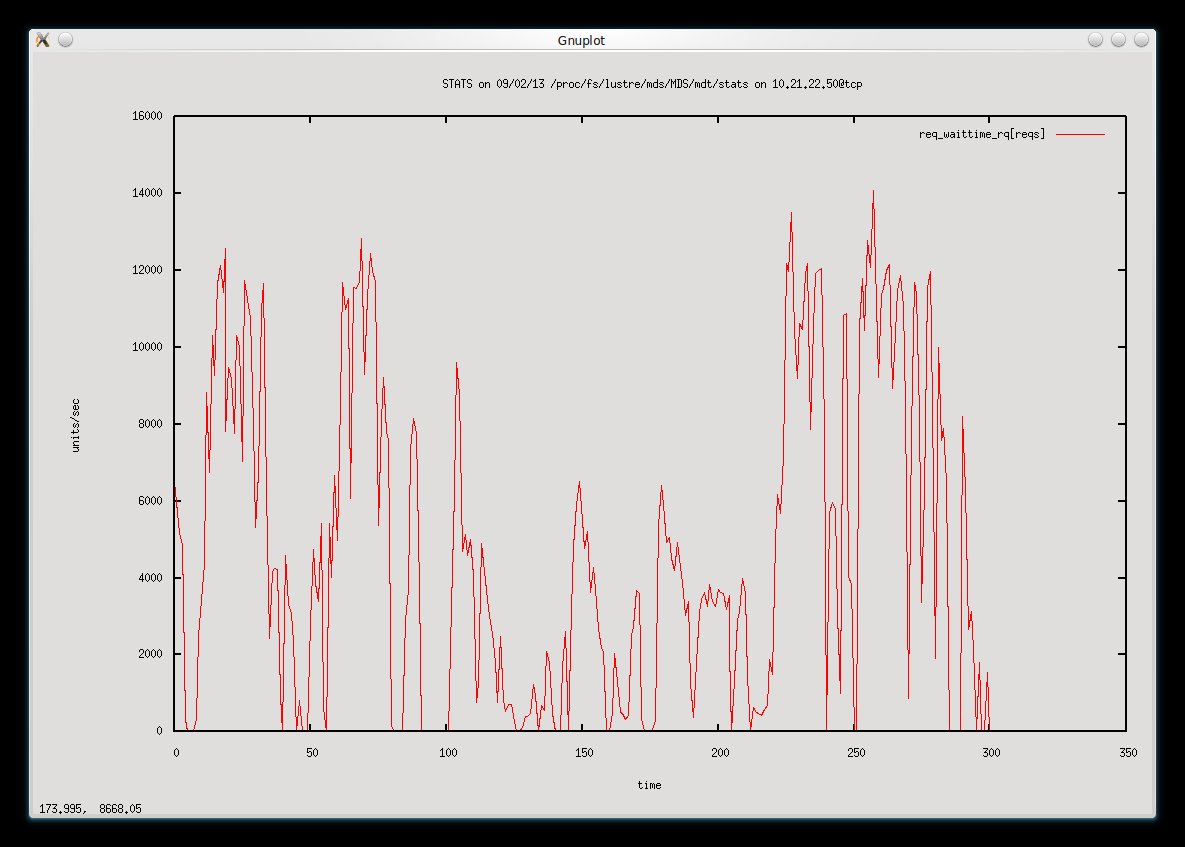
I have been investigating why our metadata rate keeps dropping to nothing every 30 seconds or so for a few seconds at a time. Looking at the debug logs it looks like it is stuck doing many osp_sync_request_commit_cb() calls. I shouldn't think this should block all other operations so maybe this is not the issue and it's just that these are the only operations that are occurring when we see the rate drop to zero. I'm pretty sure the RAID and storage path is all fine. Here is a snippet illustrating the issue:
/proc/fs/lustre/mds/MDS/mdt/stats @ 1375970781.677198
Name Cur.Count Cur.Rate #Events Unit last min avg max stddev
req_waittime 0 0 803871957 [usec] 0 2 6.63 10477 8.15
req_qdepth 0 0 803871957 [reqs] 0 0 0.00 12 0.07
req_active 0 0 803871957 [reqs] 0 1 2.67 16 1.79
req_timeout 0 0 803871957 [sec] 0 1 15.50 37 14.29
reqbuf_avail 0 0 1709293570[bufs] 0 47 63.79 64 0.59
ldlm_ibits_enqueue 0 0 499159709 [reqs] 0 1 1.00 1 0.00
mds_getattr 0 0 3152776 [usec] 0 8 346.15 1453985 6393.00
mds_getattr_lock 0 0 158194 [usec] 0 9 83.28 381776 1418.81
mds_connect 0 0 76 [usec] 0 14 3477.13 147911 21249.32
mds_disconnect 0 0 19 [usec] 0 26 1178.21 15598 3757.50
mds_getstatus 0 0 4 [usec] 0 9 13.75 16 3.20
mds_statfs 0 0 2904 [usec] 0 5 19.87 2115 67.53
mds_sync 0 0 3 [usec] 0 116 10933.67 32562 18730.69
mds_getxattr 0 0 50841 [usec] 0 6 12.89 92 3.91
obd_ping 0 0 530449 [usec] 0 3 11.87 3851 8.76
00000004:00080000:4.0:1375970781.689383:0:4870:0:(osp_sync.c:317:osp_sync_request_commit_cb()) commit req ffff8821062c4000, transno 8617232460
00000004:00080000:4.0:1375970781.689384:0:4870:0:(osp_sync.c:317:osp_sync_request_commit_cb()) commit req ffff882d394d4c00, transno 8617232461
00000004:00080000:4.0:1375970781.689384:0:4870:0:(osp_sync.c:317:osp_sync_request_commit_cb()) commit req ffff883e03485800, transno 8617232462
00000004:00080000:4.0:1375970781.689385:0:4870:0:(osp_sync.c:317:osp_sync_request_commit_cb()) commit req ffff883479fcdc00, transno 8617232463
00000004:00080000:4.0:1375970781.689386:0:4870:0:(osp_sync.c:317:osp_sync_request_commit_cb()) commit req ffff883515c1f400, transno 8617232464
00000004:00080000:4.0:1375970781.689387:0:4870:0:(osp_sync.c:317:osp_sync_request_commit_cb()) commit req ffff883d76783000, transno 8617232465
I am also attaching a graph showing the MDS rate drops over a few minutes. I can upload some full debug logs from the MDS when the rate drops to zero if that helps.
The workload is running on two clients and copies, hard links and unlinks thousands of directory trees. The two clients suffer performance drops at the same time as the MDS rate drops to zero.
Cheers,
Daire
- is related to
-
-

- Resolved
-