-
Improvement
-
Resolution: Fixed
-
 Major
Major
-
None
-
None
-
11351
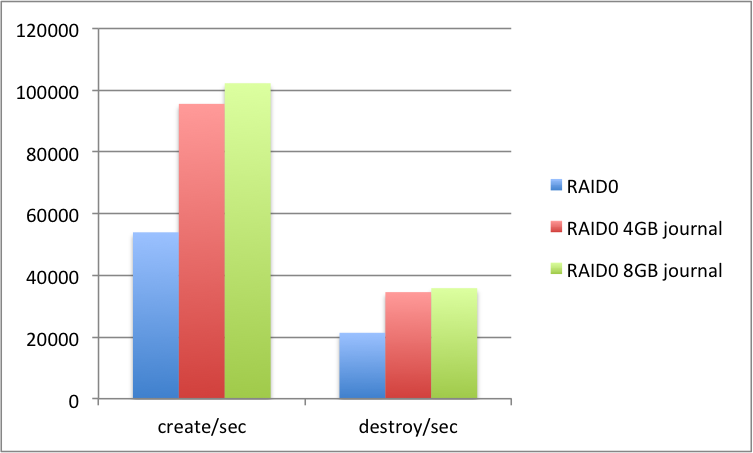
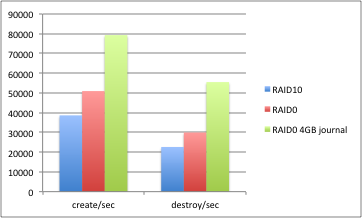
Testing has shown that a larger MDT journal size can increase performance significantly now that SMP scaling allows the MDT code to perform more operations per second. I'd like to increase the default journal size for newly formatted MDTs.
Performance test results shown with a 4GB journal size on the following hardware:
Intel(R) Xeon(R) CPU E5-2637 v2 @ 3.50GHz IVY BRIDGE 128 GB RAM 6x INTEL SSD S3700 400GB 1x Intel TrueScale Card QDR 2x Intel 82599EB 10-Gigabit SFI/SFP+ 4x Intel I350 Gigabit CentOS 6.4 Lustre 2.4.1 + CLIO simplification patch
- is related to
-
LU-4611 too many transaction credits (32279 > 25600)
-

- Resolved
-