Details
-
Bug
-
Resolution: Duplicate
-
 Blocker
Blocker
-
Lustre 2.6.0
-
3
-
13338
Description
After commit 586e95a5b3f7b9525d78e7efc9f2949387fc9d54 we have significant performance degradation in master. The following pictures show the regress measured on Xeon Phi:
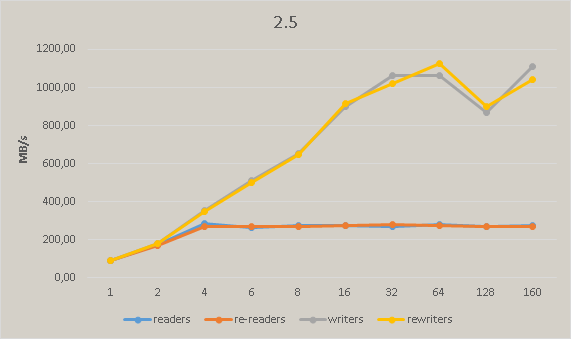
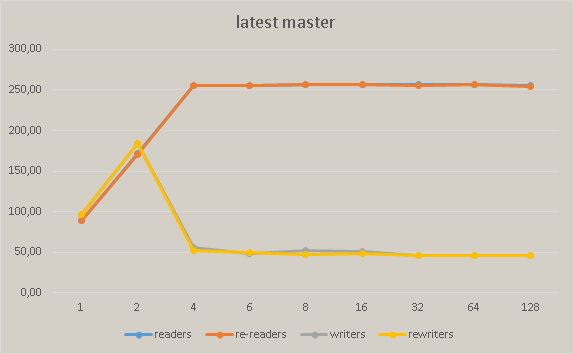
Attachments

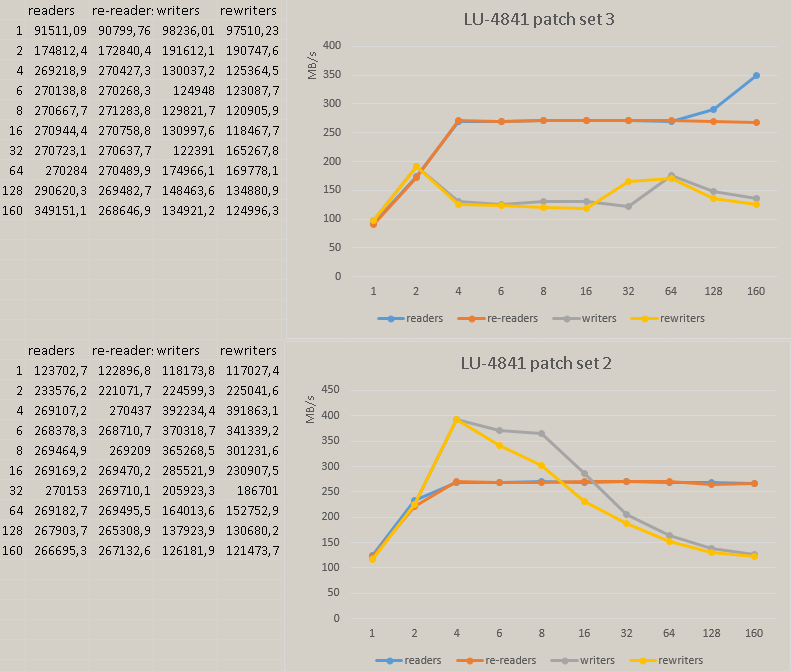

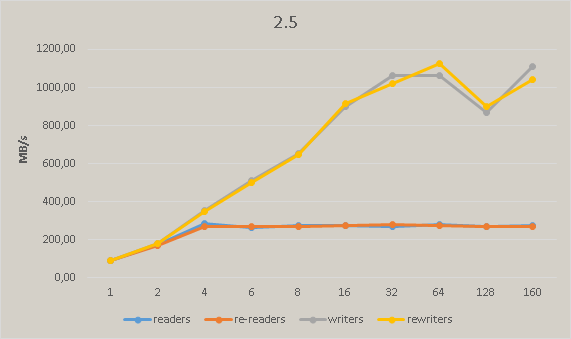

Activity
Unstable pages tracking should be turned off on I/O nodes with plenty of memory installed.
That statement is puzzling. How much memory is "plenty"? Our I/O nodes have 64GiB of RAM, which I would have thought would be considered "plenty".
But it also kind of misses the point. In the real world, it doesn't matter how much memory is installed on the node. The people who designed the system probably intended the memory to actually be used not just sit idle all the time because Lustre has no sane memory management.
On an "I/O" node, that memory needs might need to be shared by function shipping buffers, system debuggers, system management tools, and other filesystem software. On normal HPC compute nodes the memory is going to be under contention with actual user applications, other filesystems, etc.
My point is that memory contention is a normal situation in the real world. It is not a corner case. If we treat it as a corner case, we'll be putting out a subpar product.
So item 2 only happens if unstable change tracking is enabled? Or all the time?
Only when unstable pages tracking is enabled.
And 3, is that only removed when unstable change tracking is disabled? Or is that removed when it is enabled as well?
It's removed.
Also, I might wonder if the unstable page tracking setting is backwards. One offers correctness under fairly typical HPC workloads, and the other sacrifices correctness for speed. Shouldn't correctness be the default, and the speed-but-patholigically-bad-in-low-memory-situations be optional?
Unstable pages tracking should be turned off on I/O nodes with plenty of memory installed. I don't know what you mean by correctness. Actually in current implementation, it doesn't get any feedback for system memory pressure, it sends SOFT_SYNC only when it's low on available LRU slots.
Also, I might wonder if the unstable page tracking setting is backwards. One offers correctness under fairly typical HPC workloads, and the other sacrifices correctness for speed. Shouldn't correctness be the default, and the speed-but-patholigically-bad-in-low-memory-situations be optional?
Wow. In that case, that was a really terrible commit message. And probably too many things done in a single commit. So what about these two things:
2. Track unstable pages as part of LRU cache. Otherwise Lustre
can use much more memory than max_cached_mb
3. Remove obd_unstable_pages tracking to avoid using global
atomic counter
So item 2 only happens if unstable change tracking is enabled? Or all the time?
And 3, is that only removed when unstable change tracking is disabled? Or is that removed when it is enabled as well?
I didn't remove that code but just make it optional, there is a lprocfs entry to control NFS unstable pages tracking, and it's off by default.
Did you, or did you not, do the following?
Remove kernel NFS unstable pages tracking
That was a critical part of the design. Can you explain how you fixed the memory management issues without that part of the design?
And why would it be correct to make unstable pages part of the page LRU? Those pages cannot be freed. They are still in the limbo state where the server has acknowledged them, but not necessarily yet committed them to disk. When memory needs to be freed, we don't send them again, so there is no reason to walk them as part of the LRU.
Yes, I agree that it's more reasonable to take UNSTABLE pages out of LRU. However, if we didn't do that, we need to find the corresponding cl_page in brw_commit() callback and that will use an atomic operation. Actually the current mechanism is not that bad because usually there are only small part of pages are in UNSTABLE state, and those pages should stay at the tail LRU list; therefore, they shouldn't be scanned at all.
One of my concerns with using UNSTABLE pages is that it will make OST to commit transactions frequently. Therefore a problematic client will send lots of SOFT_SYNC RPCs to OSTs it talks to, which will degrade system performance significantly.
Anyway, this patch didn't remove the feature of UNSTABLE pages tracking. Users can still enable it if performance is not a problem for them.
Folks, can someone explain to me the rationale behind these changes in change 10003?
1. Remove kernel NFS unstable pages tracking because it killed performance
2. Track unstable pages as part of LRU cache. Otherwise Lustre can use much more memory than max_cached_mb
3. Remove obd_unstable_pages tracking to avoid using global atomic counter
Was not the entire point of the unstable page tracking pages to use the NFS unstable pages tracking? The idea was that it gives the Linux kernel a back pressure mechanism when memory is low. max_cached_mb has absolutely no regard for the actual memory usage of a running system; it only works in its own little lustre world.
And why would it be correct to make unstable pages part of the page LRU? Those pages cannot be freed. They are still in the limbo state where the server has acknowledged them, but not necessarily yet committed them to disk. When memory needs to be freed, we don't send them again, so there is no reason to walk them as part of the LRU.
I am rather concerned that we have thrown away correctness in pursuit of performance.
Here is the back-ported patch for Lustre b2_5 branch: http://review.whamcloud.com/12615
The patch depends on the patches for LU-3274 and LU-2139 on Lustre b2_5 branch.
Patch landed to Master. Please reopen ticket if more work is needed.
By plenty, I meant there are plenty of available memory. The memory can be temporarily `lost' when the write has completed but the transaction is not committed. Therefore, if the client has the extra memory available to hold UNSTABLE pages between two transactions, it should be able to maintain the highest write speed sustainable. Unfortunately, the exact amount of the extra memory highly depends on the performance and configuration of the OST.