Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
None
-
3
-
9223372036854775807
Description
As seen in tickets like LU-5727, we currently rely almost entirely on the good aggregate behavior of the lustre clients to avoid memory exhaustion on the MDS (and other servers, no doubt).
We require the servers, the MDS in particular, to instead limit ldlm lock usage to something reasonable to avoid OOM conditions on their own. It is not good design to leave the MDS's memory usage entirely up to the very careful administrative limiting of ldlm lock usage limits across all of the client nodes.
Consider that some sites have many thousands of clients across many clusters where such careful balancing and coordinated client limits may be difficult to achieve. Consider also WAN usages, where some clients might not ever reside at the same organization as the servers. Consider also bugs in the client, again like LU-5727.
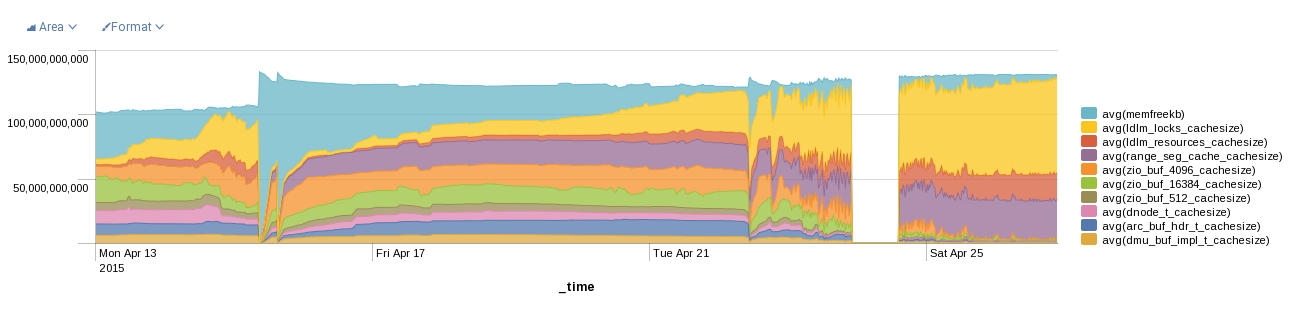
See also the attached graph showing MDS memory usage. Clearly the ldlm lock usage grows without bound, and other parts of the kernel memory usage are put under undue pressure. 70+ GiB of ldlm lock usage is not terribly reasonable for our setup.
Some might argue that the SLV code needs to be fixed, and I have no argument against pursuing that work. That could certainly be worked in some other ticket.
But even if SLV is fixed, we still require enforcement of good memory usage on the server side. There will always be client bugs or misconfiguration on clients and the server OOMing is not a reasonable response to those issues.
I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.
I am open to other solutions, of course.
Attachments
Issue Links
- is related to
-
-
- Open
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Closed
-
-
LU-11509 LDLM: replace client lock LRU with improved cache algorithm
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
-
- Resolved
-
- is related to
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
Activity
Chris, I agree that adding yet another tunable isn't ideal, but that is what you asked for ("I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.") and I agree this is a reasonable short-term solution.
Yes, I agree.
In the long term, I think the whole mechanism of calculating and using the LV from the sever needs to be examined. It isn't clear that this starts lock cancellation early enough on the clients, and whether the pressure is there to actually cancel locks. It would be useful to monitor lock volume calculations over time and under MDS memory pressure to see if it is doing anything useful at all, and fix it if not.
Yes, I was thinking of identifying least recently used locks on the server and revoking the locks directly under the indirect reclaim path. If the lock revocations are too heavy weight to even do in the indirect reclaim path, then we can certainly have an ldlm cleanup process that is woken up by the direct and/or indirect reclaim paths to do the heavy lifting.
I am not sure that the SLV concept can ever really work if it only adjusts SLV as a result of calls from the shrinker. By the time that the kernel knows that is needs to reclaim memory it is too late to impose soft, voluntary lock reductions on the clients. When the kernel needs memory we need to take the most direct actions that we can to free the memory as soon as possible.
For SLV to work reasonably at all, it would likely need to be actively monitoring system memory usage and adjusting the value to constrain aggregate lock usage well in advance of the shrinker demanding memory.
Niu, as for the LDLM pool notification, I think a DLM blocking callback on some "NULL" lock (e.g. resource 0,0,0,0) with a count and/or LV might be easily implemented as a mechanism to indicate to a client to "cancel some lock(s)", but this would need a protocol change.
Chris, I agree that adding yet another tunable isn't ideal, but that is what you asked for ("I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.") and I agree this is a reasonable short-term solution. The long term solution you propose (better integration with the kernel slab shrinkers) is exactly what the LDLM pool mechanism is supposed to do, but clearly it isn't working. Whether that is a core LDLM pool design/implementation problem, or something that has crept in over several generations of kernel slab shrinker interfaces isn't yet clear. Having a server-side LRU would potentially introduce lock contention, but maybe a per-CPU LRU would be enough, and easily implemented.
Niu, I fully agree that having a client-side max lock age is very useful, and there already is such a thing - lru_max_age. One problem is that the default age is 10h, which is much too long. It should be at most 65min - just long enough to keep files around for checkpoints every hour. If that age is not being used in the LRUR policy, then it should be.
Next, just to take a step back and state the obvious, our goal with Lustre memory management is not really to have lots of individual hard limits. We'll never get the balance of a number of fixed limits correct all the time, and we'll either have under utilized memory or still have OOMs. The bigger issue is that Lustre's memory use does not play well with the standard Linux memory reclaim mechanisms. Ultimately, we really want to be able to just set Linux's min_free_kbytes to something reasonable and not have the system OOM due the inability of the kernel to reign in its own memory use.
Since we do not currently have a way to identify ldlm locks to free under load, we must not be tying in to the kernel reclaim very well. Partly that is probably due to the fact that revoking ldlm locks requires sending RPCs. We should not do any blocking operations in the direct memory reclaim path, so it is obvious why we don't reclaim locks there. But in indirect memory reclaim, such as kswapd, it is much more reasonable to go the extra mile to reclaim locks.
So if we do the work to identify which locks can be freed, we should probably go the extra step to get that tied into the kernel indirect reclaim path. That might even obviate the need for an explicit hard lock limit.
To my understanding, the only way to connect with kernel (in)direct reclaim mechanism is the registered slab shrinker, when kernel is under memory pressure (or kswapd wants to reclaim memory), the shrinker will be called to inform the slab user to free objects. The shrinker interface doesn't fit into the ldlm server lock very well, because kernel assumes the objects being freed in the shrinker and the number of freed objects being returned by shrinker, however, server lock shrinker can only inform clients to cancel locks (or revoke locks), server locks won't be freed instantly unless we wait in the shrinker until all things done. (I think it's impractical to block the shrinker for that long time even with the indirect reclaim path, imagine if some clients failed to response, it has to wait for the clients being evicted) So the best we can do with the shrinker is to inform clients to cancel locks (or choose some locks to revoke them).
Lustre do have shrinker for ldlm server locks, it just decrease the SLV and hope client start to cancel locks when they are aware of this decreasing. This scheme seems doesn't work well so far, because:
1. How much the SLV should be decreased? Current formulation looks not correct.
2. The decreased SLV can only be propagated to clients on next RPC reply (PING or some random RPC from client), that's a relatively long time, to make it worse, the SLV is likely to be bumped back by the recalculation thread in this period of time.
I think we may consider to decouple the shrinker with SLV to make sure the shrinker working as expected, there are two ways to reconstruct the shrinker:
1. Inform client to cancel certain locks: We'd manage to inform clients that server wants some locks to be reclaimed immediately, and client should choose & cancel certain amount of unused locks once it get this notification (no matter how much the SLV/CLV is).
The advantage of this method is that client always knows better which locks are unused than server, and the lock choosing work can be offloaded to clients. The problem is how to inform all clients effectively and instantly rather than replying on PING? An idea in my mind is to use a global ldlm lock like quota does. (each client enqueue a global lock, and server informs clients by glimpse callback) Actually this global lock can be a generic tunnel (server -> client) for all kinds of other purposes, but I'm not sure how much complexity it'll bring us.
2. Server identify unused locks and send blocking ast to them directly. This way looks require less code changes.
Chris, I think this is the "extra step to get that tied into the kernel indirect reclaim path" you mentioned? Am I understanding right?
All, any thoughts/comments?
I had a conversation with Brian here, and I want to share some thoughts from that:
First, perhaps we just need to add an LRU for ldlm locks. Ultimately that makes the lock reclaim decisions much easier than searching the hash. You have already found ways to more than offset the size increase in the ldlm_lock structure to account for LRU pointers.
Next, just to take a step back and state the obvious, our goal with Lustre memory management is not really to have lots of individual hard limits. We'll never get the balance of a number of fixed limits correct all the time, and we'll either have under utilized memory or still have OOMs. The bigger issue is that Lustre's memory use does not play well with the standard Linux memory reclaim mechanisms. Ultimately, we really want to be able to just set Linux's min_free_kbytes to something reasonable and not have the system OOM due the inability of the kernel to reign in its own memory use.
Since we do not currently have a way to identify ldlm locks to free under load, we must not be tying in to the kernel reclaim very well. Partly that is probably due to the fact that revoking ldlm locks requires sending RPCs. We should not do any blocking operations in the direct memory reclaim path, so it is obvious why we don't reclaim locks there. But in indirect memory reclaim, such as kswapd, it is much more reasonable to go the extra mile to reclaim locks.
So if we do the work to identify which locks can be freed, we should probably go the extra step to get that tied into the kernel indirect reclaim path. That might even obviate the need for an explicit hard lock limit.
And then there are probably lots of other areas in lustre where similar lock reclaim needs to be enabled to work well with the normal kernel mechanisms. But locks are still a really good place to start since they are obviously a large issue in production for us.
Lots of good ideas here. I would like to emphasize that we want the lock limit work done before the other improvements like shrinking ldlm_lock. I think the shrinking of ldlm_lock is worthy of a separate jira ticket.
For the proc tunable, I think we really want that to be a size (bytes) rather than a lock count limit. Converting a size limit into a count limit is easy for code, but is difficult for humans (system administrators).
I do agree that we'll need to free more than one lock at a time when the limit is hit.
Thank you for all these ideas, Andreas. I'll start with these safety approaches. Besides all these approaches, I think we may consider adding a "maximum lock age" to the LRUR policy, which means if a lock is not used for a enough long time, it should be cancelled no matter if it's CLV is greater than SLV, which guarantees client can always cancel some unused locks in timely manner before the SLV is fixed, and I think it does make sense even if the SLV is fixed.
Niu, I think there are a couple of potential approaches to fixing this. I think the ultimate goal is to fix the existing "lock volume pool" handling so that clients are asked to cancel locks from their LRU in a timely manner before the MDS is running out of memory. However, it also makes sense to implement a safety net, which will be easier understand and ensure correctness, faster to implement and port to older Lustre releases, and will still be useful in case the "lock volume pool" approach isn't working properly (as it is today).
I think the first and easiest thing to look at is whether it is possible to change ldlm_new_lock() to force an "old" lock to be freed (cancelled) if there are "too many" locks. This will ensure that when there are too many locks on the server, one lock will be cancelled for each new lock that is granted. It is straight forward to add a /proc tunable to the server namespace (lock_count_max?) that defines the absolute maximum number of locks. This should default to something reasonable (maybe 1/8 or 1/10 of RAM based on roundup_pow_of_two(sizeof(struct ldlm_lock))) and should be a global percpu_counter so that we don't need to balance lock allocations across namespaces, while still avoiding CPU contention on a single counter.
The more difficult part is how to find "old" locks on the server. There is no ideal way to do this, because the server doesn't see which locks are in use by the client, but it can at least make a guess. One option is to grab an old resource from the namespace, and cancel one or more locks from the end of the lr_granted list, which should be roughly in LRU order. The hard part is finding the oldest resource in the namespace, since these are kept in a hash. While not necessarily the best way to find a lock, the cost to any single client should be relatively low, and not worse than any other kind of lock contention. There would be some overhead from locking and searching the namespace, but it is still better than OOM, and if several locks are cancelled at once (e.g. min(100 locks, locks on resource), excluding locks with l_last_activity or l_last_used within 30s[*]) the per-lock overhead can be reduced. The other option is to find some way to pick random resources from the ns_hash, and then cancel the oldest half of the locks. This cannot start at the same place each time, or the same resources would be candidates for cancellation repeatedly.
[*] it looks like ldlm_refresh_waiting_lock() should also update l_last_activity, maybe by moving this update into __ldlm_add_waiting_lock so that l_last_activity is updated whenever a client sends an RPC to that object, so this code can make a better decision. Alternately, the server could also update l_last_used on so that the lock scanning can have a better chance of finding an old lock.
Another minor improvement that is possible is to shrink the size of ldlm_resource, by filling in holes in the structure. The current size is 320 bytes, with 12 bytes of holes (use "pahole lustre/ptlrpc/ptlrpc.ko" from the "dwarves" RPM to see this). Moving lr_refcount after lr_lock would remove 8 bytes of holes. Removing the unused lr_most_restr field would save another 16 bytes. That would allow 13 ldlm_resource structures to fit into a 4096-byte page instead of only 12. Making lr_itree optional (e.g. allocating it from its own slab in ldlm_extent_add_lock() only for extent locks, and making the pointer to it a union with lr_lvb_inode which is only used on the client) would reduce the size by 128 bytes, and allow 24 ldlm_resource structures per 4096-byte page, saving about 15GB on the MDS in the graph.
Shrinking ldlm_lock to fit more per slab would be a bit harder, but would be worthwhile because there are so many locks and would save many MB of space on the server. The ldlm_*callback pointers could be replaced by a single ldlm_callback_suite pointer, since these are always the same, saving 16 bytes. The l_exp_flock_hash and l_tree_node are used on different lock types, and are only used on the server. l_lru, l_conn_export, and l_lvb* only used on the client, while l_export is only used on the server. There are also a number of other fields in ldlm_lock already listed as being client- or server-only Putting these in a union could save a lot of space. This is relatively more complex to do and should be in a separate bug, and discussed with Alex.
It wouldn't hurt to try changing ldlm_lock_new() to use GFP_KERNEL for locks allocated on a server namespace. The same could be done for ldlm_resource_new() if it was passed the namespace as an argument. While this won't directly cause lock cancellations from the server, it will allow these threads to call slab shrinkers that may free up other memory and also put pressure on the LDLM slabs to free other client locks via the pool mechanism. I don't think this will cause problems, since lock allocations are not done under memory pressure (all dirty files should already hold a lock when trying to flush pages from memory), so even with a client and server on the same node there shouldn't be a risk of deadlocks.
I agree, 10h is too long, and now it's only used for AGED policy (when lru_resize not enabled). I'll add it for LRUR.
Yes, I think we may need this in the long-term solution.
Totally agreed, that's why I want to decouple the SLV mechanism with shrinker.
Yes, I think that was the design goal of SLV, but looks it didn't work as expected.
Now looks the conclusion are:
Short-term solution:
Long-term solution:
Let's start with the short-term solution.