Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
None
-
3
-
9223372036854775807
Description
As seen in tickets like LU-5727, we currently rely almost entirely on the good aggregate behavior of the lustre clients to avoid memory exhaustion on the MDS (and other servers, no doubt).
We require the servers, the MDS in particular, to instead limit ldlm lock usage to something reasonable to avoid OOM conditions on their own. It is not good design to leave the MDS's memory usage entirely up to the very careful administrative limiting of ldlm lock usage limits across all of the client nodes.
Consider that some sites have many thousands of clients across many clusters where such careful balancing and coordinated client limits may be difficult to achieve. Consider also WAN usages, where some clients might not ever reside at the same organization as the servers. Consider also bugs in the client, again like LU-5727.
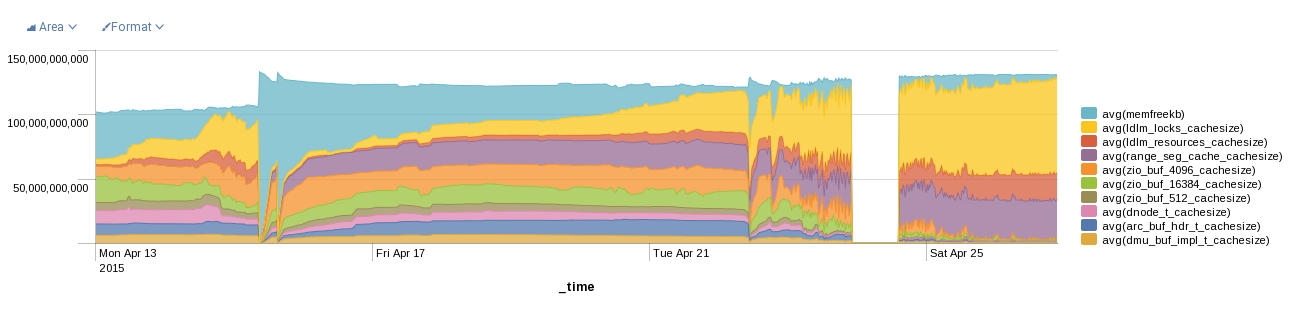
See also the attached graph showing MDS memory usage. Clearly the ldlm lock usage grows without bound, and other parts of the kernel memory usage are put under undue pressure. 70+ GiB of ldlm lock usage is not terribly reasonable for our setup.
Some might argue that the SLV code needs to be fixed, and I have no argument against pursuing that work. That could certainly be worked in some other ticket.
But even if SLV is fixed, we still require enforcement of good memory usage on the server side. There will always be client bugs or misconfiguration on clients and the server OOMing is not a reasonable response to those issues.
I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.
I am open to other solutions, of course.
Attachments
Issue Links
- is related to
-
-
- Open
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Closed
-
-
LU-11509 LDLM: replace client lock LRU with improved cache algorithm
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
-
- Resolved
-
- is related to
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
Activity
Niu Yawei (yawei.niu@intel.com) uploaded a new patch: http://review.whamcloud.com/14931
Subject: LU-6529 ldlm: reclaim granted locks defensively
Project: fs/lustre-release
Branch: master
Current Patch Set: 1
Commit: 3e12dd88fd850ab2afe4b0e6215cae7bea136729
Oleg Drokin (oleg.drokin@intel.com) merged in patch http://review.whamcloud.com/14856/
Subject: LU-6529 ldlm: cancel aged locks for LRUR
Project: fs/lustre-release
Branch: master
Current Patch Set:
Commit: 0356990876308f811cc6c61c22946a1cd73e5c23
There will be two patches for the short-term solution, the first one has been posted, I'm working on the second one, most coding is done, will push it soon.
Niu Yawei (yawei.niu@intel.com) uploaded a new patch: http://review.whamcloud.com/14856
Subject: LU-6529 ldlm: cancel aged locks for LRUR
Project: fs/lustre-release
Branch: master
Current Patch Set: 1
Commit: b97f9efbb700f04b9a355e6ac4cbfc751d8ab411
Niu, I fully agree that having a client-side max lock age is very useful, and there already is such a thing - lru_max_age. One problem is that the default age is 10h, which is much too long. It should be at most 65min - just long enough to keep files around for checkpoints every hour. If that age is not being used in the LRUR policy, then it should be.
I agree, 10h is too long, and now it's only used for AGED policy (when lru_resize not enabled). I'll add it for LRUR.
Niu, as for the LDLM pool notification, I think a DLM blocking callback on some "NULL" lock (e.g. resource 0,0,0,0) with a count and/or LV might be easily implemented as a mechanism to indicate to a client to "cancel some lock(s)", but this would need a protocol change.
Yes, I think we may need this in the long-term solution.
I am not sure that the SLV concept can ever really work if it only adjusts SLV as a result of calls from the shrinker. By the time that the kernel knows that is needs to reclaim memory it is too late to impose soft, voluntary lock reductions on the clients. When the kernel needs memory we need to take the most direct actions that we can to free the memory as soon as possible.
Totally agreed, that's why I want to decouple the SLV mechanism with shrinker.
For SLV to work reasonably at all, it would likely need to be actively monitoring system memory usage and adjusting the value to constrain aggregate lock usage well in advance of the shrinker demanding memory.
Yes, I think that was the design goal of SLV, but looks it didn't work as expected.
Now looks the conclusion are:
Short-term solution:
- Adding tunable limit on server side, identify unused locks then revoke them when lock count reaching the limit.
- Adding maximum lock age on client side for the LRUR policy.
Long-term solution:
- Adding proc entries to monitor LV changes and statistics of locks being cancelled by LRUR.
- Identify problems in the LV mechanism and fix them.
- Change the server lock shrinker to notify clients instantly (no SLV involved).
Let's start with the short-term solution.
Chris, I agree that adding yet another tunable isn't ideal, but that is what you asked for ("I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.") and I agree this is a reasonable short-term solution.
Yes, I agree.
In the long term, I think the whole mechanism of calculating and using the LV from the sever needs to be examined. It isn't clear that this starts lock cancellation early enough on the clients, and whether the pressure is there to actually cancel locks. It would be useful to monitor lock volume calculations over time and under MDS memory pressure to see if it is doing anything useful at all, and fix it if not.
Yes, I was thinking of identifying least recently used locks on the server and revoking the locks directly under the indirect reclaim path. If the lock revocations are too heavy weight to even do in the indirect reclaim path, then we can certainly have an ldlm cleanup process that is woken up by the direct and/or indirect reclaim paths to do the heavy lifting.
I am not sure that the SLV concept can ever really work if it only adjusts SLV as a result of calls from the shrinker. By the time that the kernel knows that is needs to reclaim memory it is too late to impose soft, voluntary lock reductions on the clients. When the kernel needs memory we need to take the most direct actions that we can to free the memory as soon as possible.
For SLV to work reasonably at all, it would likely need to be actively monitoring system memory usage and adjusting the value to constrain aggregate lock usage well in advance of the shrinker demanding memory.
Niu, as for the LDLM pool notification, I think a DLM blocking callback on some "NULL" lock (e.g. resource 0,0,0,0) with a count and/or LV might be easily implemented as a mechanism to indicate to a client to "cancel some lock(s)", but this would need a protocol change.
Chris, I agree that adding yet another tunable isn't ideal, but that is what you asked for ("I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.") and I agree this is a reasonable short-term solution. The long term solution you propose (better integration with the kernel slab shrinkers) is exactly what the LDLM pool mechanism is supposed to do, but clearly it isn't working. Whether that is a core LDLM pool design/implementation problem, or something that has crept in over several generations of kernel slab shrinker interfaces isn't yet clear. Having a server-side LRU would potentially introduce lock contention, but maybe a per-CPU LRU would be enough, and easily implemented.
Niu, I fully agree that having a client-side max lock age is very useful, and there already is such a thing - lru_max_age. One problem is that the default age is 10h, which is much too long. It should be at most 65min - just long enough to keep files around for checkpoints every hour. If that age is not being used in the LRUR policy, then it should be.
Oleg Drokin (oleg.drokin@intel.com) merged in patch http://review.whamcloud.com/14931/
Subject:
LU-6529ldlm: reclaim granted locks defensivelyProject: fs/lustre-release
Branch: master
Current Patch Set:
Commit: fe60e0135ee2334440247cde167b707b223cf11d