-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
None
-
3
-
9223372036854775807
As seen in tickets like LU-5727, we currently rely almost entirely on the good aggregate behavior of the lustre clients to avoid memory exhaustion on the MDS (and other servers, no doubt).
We require the servers, the MDS in particular, to instead limit ldlm lock usage to something reasonable to avoid OOM conditions on their own. It is not good design to leave the MDS's memory usage entirely up to the very careful administrative limiting of ldlm lock usage limits across all of the client nodes.
Consider that some sites have many thousands of clients across many clusters where such careful balancing and coordinated client limits may be difficult to achieve. Consider also WAN usages, where some clients might not ever reside at the same organization as the servers. Consider also bugs in the client, again like LU-5727.
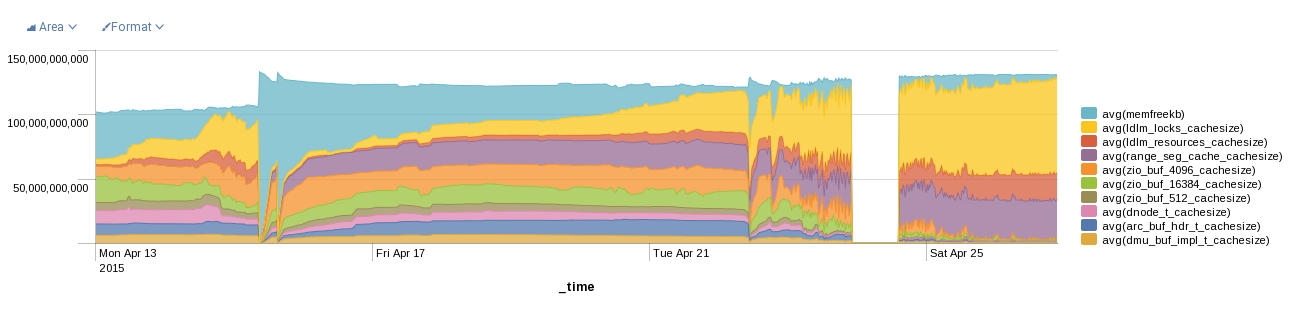
See also the attached graph showing MDS memory usage. Clearly the ldlm lock usage grows without bound, and other parts of the kernel memory usage are put under undue pressure. 70+ GiB of ldlm lock usage is not terribly reasonable for our setup.
Some might argue that the SLV code needs to be fixed, and I have no argument against pursuing that work. That could certainly be worked in some other ticket.
But even if SLV is fixed, we still require enforcement of good memory usage on the server side. There will always be client bugs or misconfiguration on clients and the server OOMing is not a reasonable response to those issues.
I would propose a configurable hard limit on the number of locks (or space used by locks) on the server side.
I am open to other solutions, of course.
- is related to
-
-
- Open
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Closed
-
-
LU-19264 LRU Inconsistency in Client-Server Distributed Lock Caching
-

- Open
-
-
LU-11509 LDLM: replace client lock LRU with improved cache algorithm
-
- Open
-
-
-
- Open
-
-
-
- Open
-
-
-
- Resolved
-
- is related to
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-