Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Lustre 2.7.0
-
[root@panda-oss-25-4 ~]# uname -a
Linux panda-oss-25-4.sdsc.edu 3.10.73-1.el6.elrepo.x86_64 #1 SMP Thu Mar 26 16:28:30 EDT 2015 x86_64 x86_64 x86_64 GNU/Linux
[root@panda-oss-25-4 ~]# rpm -aq | grep lustre
lustre-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
lustre-osd-zfs-mount-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
lustre-iokit-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
lustre-source-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
lustre-osd-zfs-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
lustre-modules-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
lustre-tests-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
[ root@panda-oss-25-4 ~]# uname -a Linux panda-oss-25-4.sdsc.edu 3.10.73-1.el6.elrepo.x86_64 #1 SMP Thu Mar 26 16:28:30 EDT 2015 x86_64 x86_64 x86_64 GNU/Linux [ root@panda-oss-25-4 ~]# rpm -aq | grep lustre lustre-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64 lustre-osd-zfs-mount-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64 lustre-iokit-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64 lustre-source-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64 lustre-osd-zfs-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64 lustre-modules-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64 lustre-tests-2.7.51-3.10.73_1.el6.elrepo.x86_64_gb019b03.x86_64
-
4
-
9223372036854775807
Description
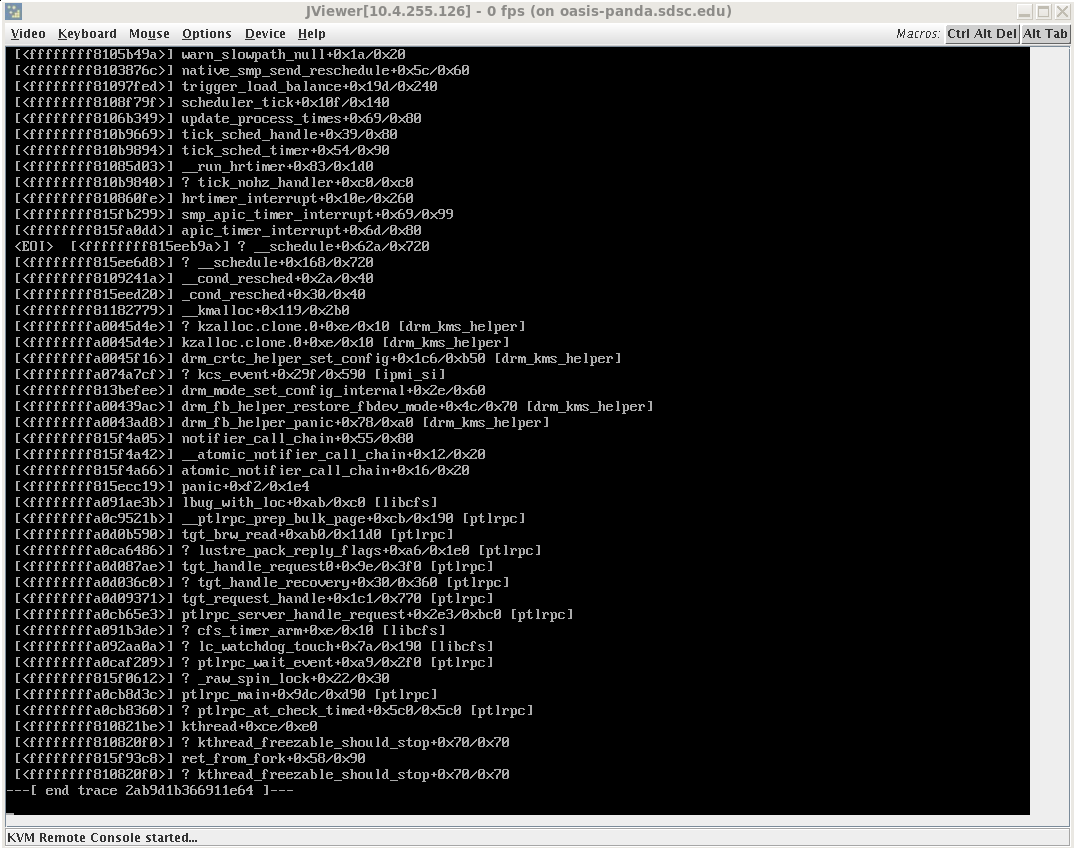
No sign or indication, ie lustre-log or error messages, OSS unexpectantly crash (please see console image).
/var/log/messages is attached