-
Improvement
-
Resolution: Fixed
-
 Critical
Critical
-
None
-
Lustre 2.9.0
-
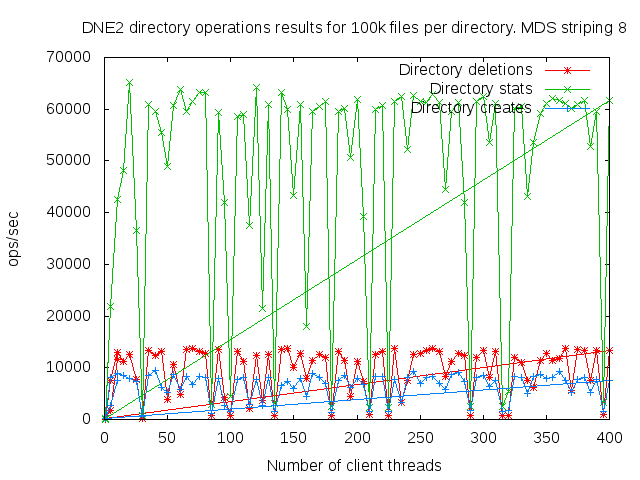
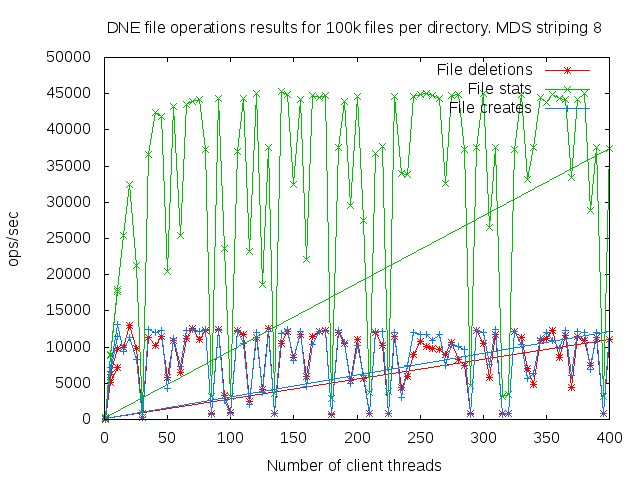
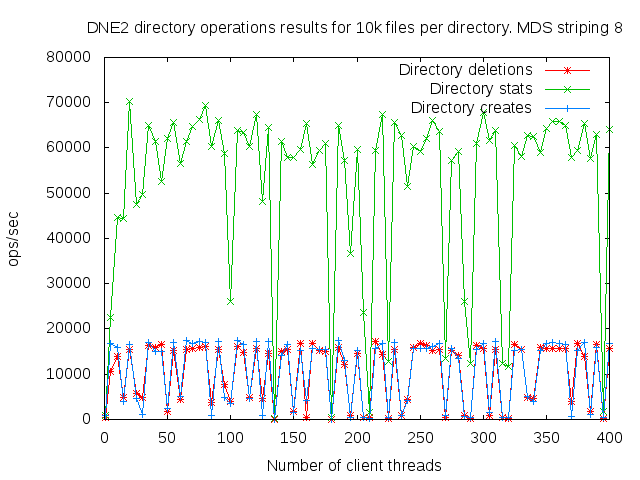
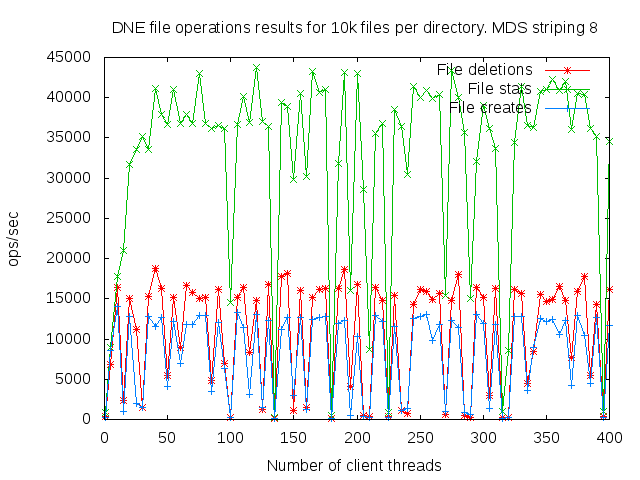
DNE2 system with up to 16 MDS servers. Uses up to 400 client nodes spread across 20 physical nodes. All the results are based on mdtest 1.9.3 runs.
-
9223372036854775807
I did a detail study of the client scaling behavior for 10k and 100k files per directory using 1,2,4, and 8 MDS servers each having one MDT. I also attempted to collect dat for 16 MDS servers but the results were so bad I didn't both to finish collecting them since it would take several months to finish the 16 node case.
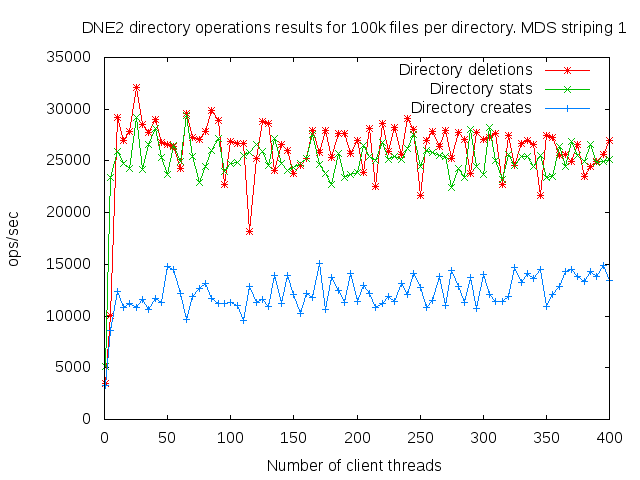
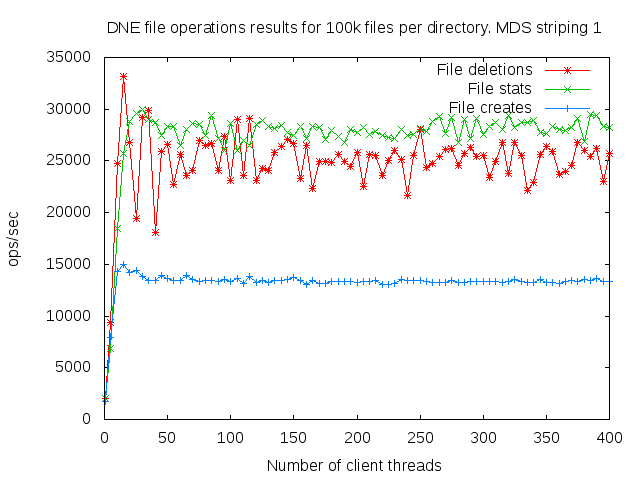
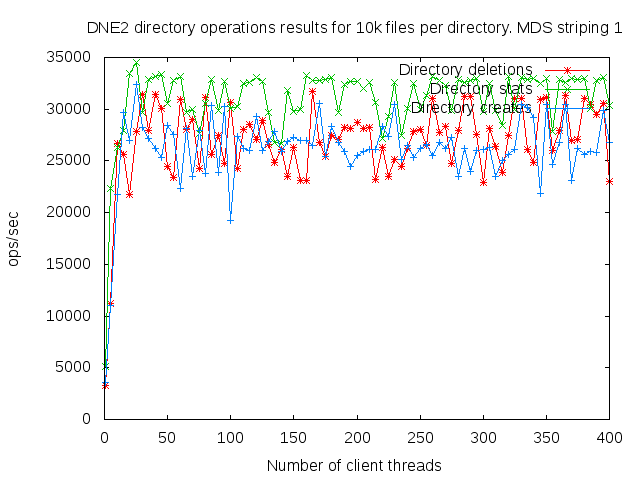
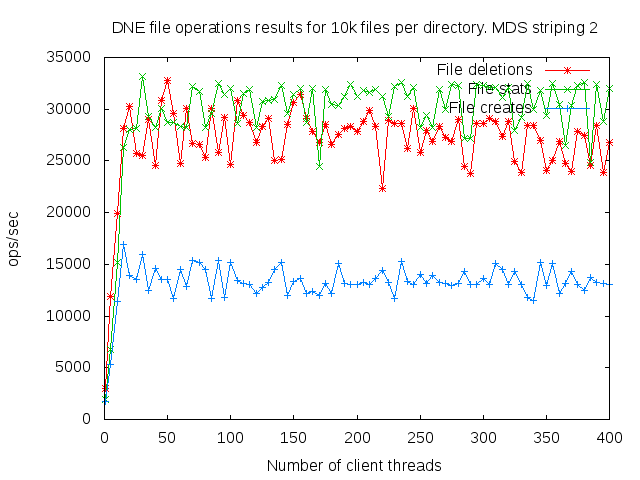
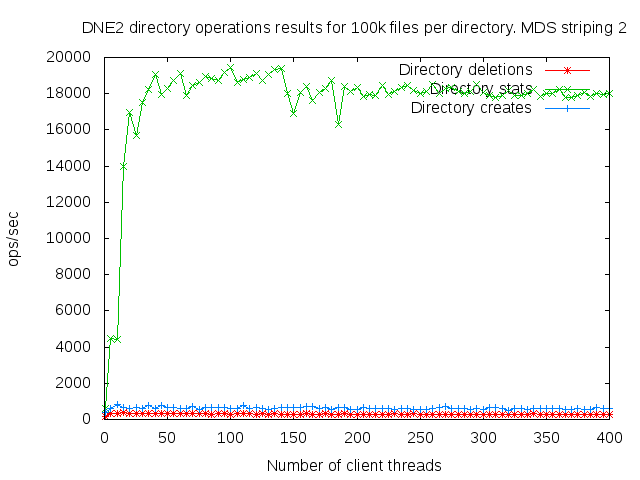
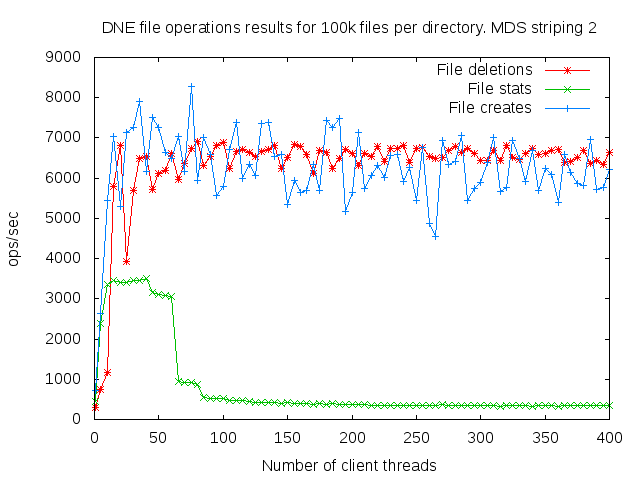
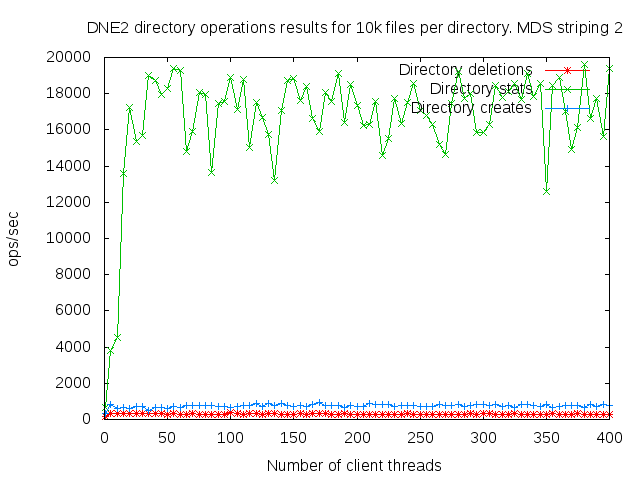
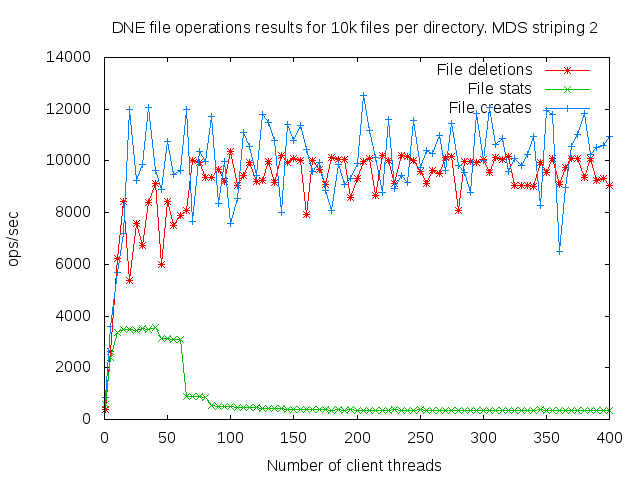
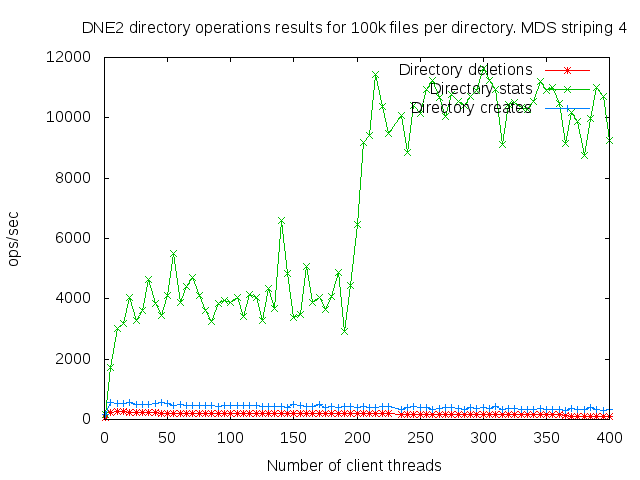
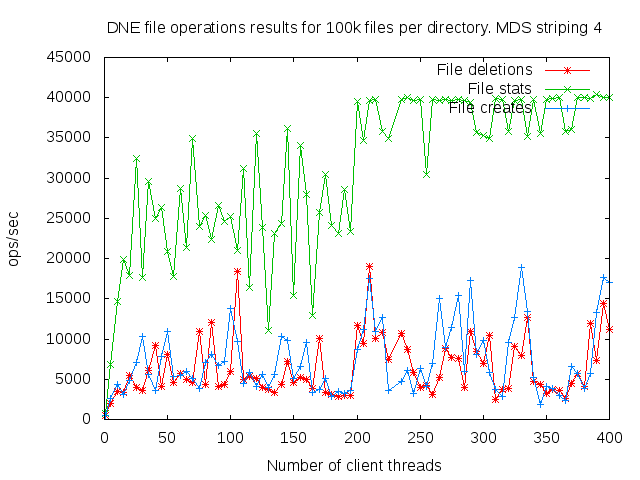
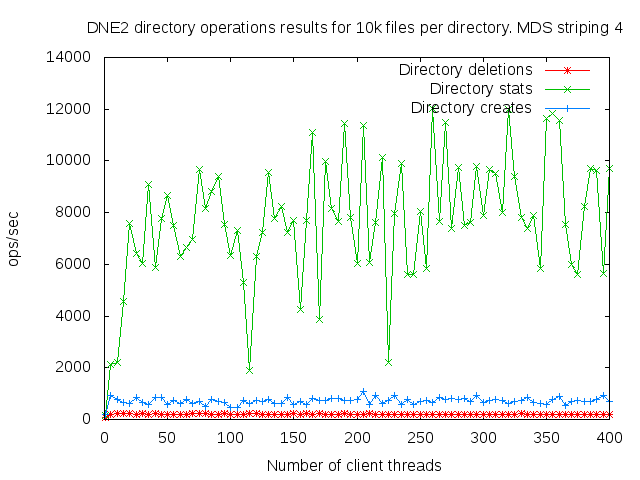
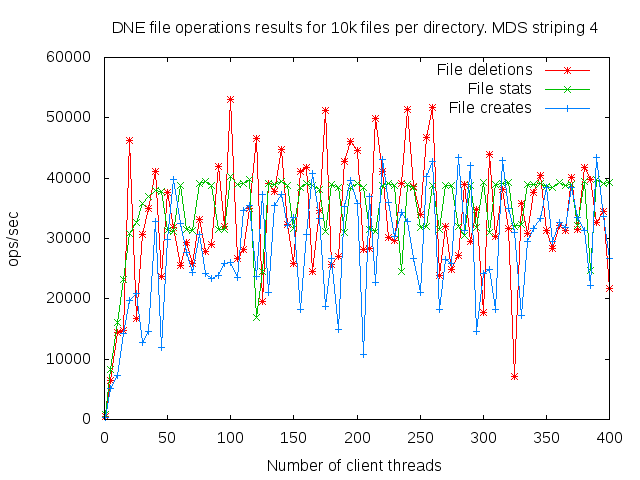
- is related to
-
LU-6831 The ticket for tracking all DNE2 bugs
-

- Reopened
-