Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Lustre 2.1.0, Lustre 2.2.0, Lustre 2.4.0, Lustre 1.8.6
-
3
-
5914
Description
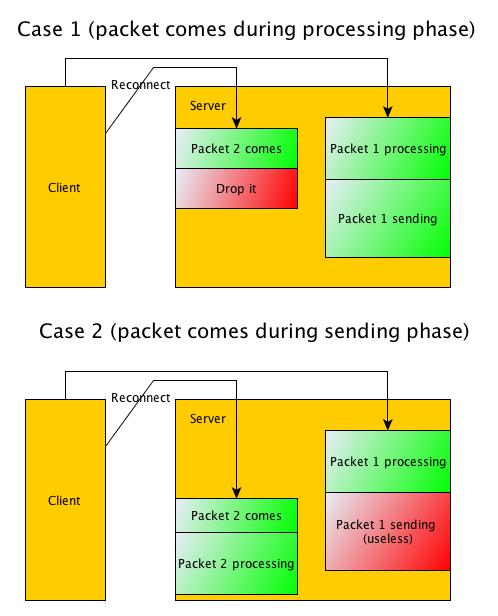
While originally this was a useful workaround, it created a lot of other unintended problems.
This code must be disabled and instead we just should disable handling several duplicate requests at the same time.
Attachments
Issue Links
- duplicates
-
-

- Resolved
-
- is related to
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Closed
-
- Trackbacks
-
![[Confluence: Engineering]](/images/icons/generic_link_16.png "[Confluence: Engineering]") Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA
Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA
Activity
This patch doesn't work properly with bulk resends because bulks use new XID always, even for RESENT case. Therefore we cannot match original request that might be processed on server at the same time. It is not clear how to solve this in simple way in context of this patch, looks like patch should be reworked and will be more complex, e.g. we might need to change protocol and store original XID in bulk along with new one.
Btw, the comment about bulk XID and replated code:
int ptlrpc_register_bulk(struct ptlrpc_request *req) { ... /* An XID is only used for a single request from the client. * For retried bulk transfers, a new XID will be allocated in * in ptlrpc_check_set() if it needs to be resent, so it is not * using the same RDMA match bits after an error. */ ... } and void ptlrpc_resend_req(struct ptlrpc_request *req) { DEBUG_REQ(D_HA, req, "going to resend"); lustre_msg_set_handle(req->rq_reqmsg, &(struct lustre_handle){ 0 }); req->rq_status = -EAGAIN; spin_lock(&req->rq_lock); req->rq_resend = 1; req->rq_net_err = 0; req->rq_timedout = 0; if (req->rq_bulk) { __u64 old_xid = req->rq_xid; /* ensure previous bulk fails */ req->rq_xid = ptlrpc_next_xid(); CDEBUG(D_HA, "resend bulk old x"LPU64" new x"LPU64"\n", old_xid, req->rq_xid); } ptlrpc_client_wake_req(req); spin_unlock(&req->rq_lock); }
Since Andreas recommended to merge Mikhail patch and mine I updated http://review.whamcloud.com/#change,4960 with improvement request.
Hi gents,
here is a patch version for this issue from our team:
http://review.whamcloud.com/#change,5054
Cliff, the refused-reconnection problem is the after-effect of whatever problem happened, and there are many ways it can be triggered. You should open a separate bug report for the initial problem of the server going unresponsive, or whatever happened.
Here is a call trace from a client, while the MDS is reporting the RPC issue:
2013-01-15 09:45:57 INFO: task mdtest:6078 blocked for more than 120 seconds. 2013-01-15 09:45:57 "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message. 2013-01-15 09:45:57 mdtest D 0000000000000003 0 6078 6074 0x00000000 2013-01-15 09:45:57 ffff88017ede7c58 0000000000000086 0000000000000000 0000000000000086 2013-01-15 09:45:57 ffff88030aa62a20 ffff8801c5851960 ffffffff81aa5740 0000000000000286 2013-01-15 09:45:57 ffff8801bba69ab8 ffff88017ede7fd8 000000000000fb88 ffff8801bba69ab8 2013-01-15 09:45:57 Call Trace: 2013-01-15 09:45:57 [<ffffffff814ff6fe>] __mutex_lock_slowpath+0x13e/0x180 2013-01-15 09:45:57 [<ffffffff814ff59b>] mutex_lock+0x2b/0x50 2013-01-15 09:45:57 [<ffffffffa07eb80c>] mdc_reint+0x3c/0x3b0 [mdc] 2013-01-15 09:45:57 [<ffffffffa07ec880>] mdc_unlink+0x1b0/0x500 [mdc] 2013-01-15 09:45:57 [<ffffffffa0a5feb9>] lmv_unlink+0x199/0x7e0 [lmv] 2013-01-15 09:45:57 [<ffffffffa097dba6>] ll_unlink+0x176/0x670 [lustre] 2013-01-15 09:45:57 [<ffffffff8118923f>] vfs_unlink+0x9f/0xe0 2013-01-15 09:45:57 [<ffffffff81187f8a>] ? lookup_hash+0x3a/0x50 2013-01-15 09:45:57 [<ffffffff8118b773>] do_unlinkat+0x183/0x1c0 2013-01-15 09:45:57 [<ffffffff8119a960>] ? mntput_no_expire+0x30/0x110 2013-01-15 09:45:57 [<ffffffff8100c5b5>] ? math_state_restore+0x45/0x60 2013-01-15 09:45:57 [<ffffffff8118b7c6>] sys_unlink+0x16/0x20 2013-01-15 09:45:57 [<ffffffff8100b0f2>] system_call_fastpath+0x16/0x1b
I am still experiencing this issue on Hyperion, especially using mdtest file-per-process. In the last test, starting seeing these timeouts prior to the actual error.
Jan 14 22:35:08 hyperion-rst6 kernel: LNet: Service thread pid 11870 was inactive for 200.00s. The thread might be hung, or it might only be slow and will resume later. Dumping the stack trace for debugging purposes: Jan 14 22:35:08 hyperion-rst6 kernel: Pid: 11870, comm: mdt03_001 Jan 14 22:35:08 hyperion-rst6 kernel: Jan 14 22:35:08 hyperion-rst6 kernel: Call Trace: Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa06cf072>] start_this_handle+0x282/0x500 [jbd2] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffff81092170>] ? autoremove_wake_function+0x0/0x40 Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa06cf4f0>] jbd2_journal_start+0xd0/0x110 [jbd2] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa072bab8>] ldiskfs_journal_start_sb+0x58/0x90 [ldiskfs] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa072be7c>] ldiskfs_dquot_initialize+0x4c/0xc0 [ldiskfs] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0708590>] ? ldiskfs_delete_inode+0x0/0x250 [ldiskfs] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffff811968a3>] generic_delete_inode+0x173/0x1d0 Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffff81196965>] generic_drop_inode+0x65/0x80 Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffff811957b2>] iput+0x62/0x70 Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0e3fc24>] osd_object_delete+0x1d4/0x2f0 [osd_ldiskfs] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa07e6059>] lu_object_free+0x89/0x1a0 [obdclass] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa03a5351>] ? libcfs_debug_msg+0x41/0x50 [libcfs] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa03aa5d2>] ? cfs_hash_bd_from_key+0x42/0xd0 [libcfs] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa07e690d>] lu_object_put+0xad/0x320 [obdclass] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0f2c69d>] mdt_object_unlock_put+0x3d/0x110 [mdt] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0f4e0d7>] mdt_reint_unlink+0x637/0x850 [mdt] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0965fce>] ? lustre_pack_reply_flags+0xae/0x1f0 [ptlrpc] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0f48cf1>] mdt_reint_rec+0x41/0xe0 [mdt] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0f423a3>] mdt_reint_internal+0x4e3/0x7d0 [mdt] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0f426d4>] mdt_reint+0x44/0xe0 [mdt] Jan 14 22:35:08 hyperion-rst6 kernel: [<ffffffffa0f31a72>] mdt_handle_common+0x8e2/0x1680 [mdt] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa0f67a25>] mds_regular_handle+0x15/0x20 [mdt] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa09761ec>] ptlrpc_server_handle_request+0x41c/0xdf0 [ptlrpc] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa039564e>] ? cfs_timer_arm+0xe/0x10 [libcfs] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa096d669>] ? ptlrpc_wait_event+0xa9/0x290 [ptlrpc] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffff81053463>] ? __wake_up+0x53/0x70 Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa0977776>] ptlrpc_main+0xbb6/0x1950 [ptlrpc] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa0976bc0>] ? ptlrpc_main+0x0/0x1950 [ptlrpc] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffff8100c14a>] child_rip+0xa/0x20 Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa0976bc0>] ? ptlrpc_main+0x0/0x1950 [ptlrpc] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffffa0976bc0>] ? ptlrpc_main+0x0/0x1950 [ptlrpc] Jan 14 22:35:09 hyperion-rst6 kernel: [<ffffffff8100c140>] ? child_rip+0x0/0x20
http://review.whamcloud.com/#change,4960
I've just updated old patch to be compatible with new master code. It provides the same functionality as old one so far, without any attempts to use new reply buffers while answering on older request.
patch was refreshed http://review.whamcloud.com/#/c/4960/. I doesn't handle bulk request for now, this will be solved in the following patch.