Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Lustre 2.1.0, Lustre 2.2.0, Lustre 2.4.0, Lustre 1.8.6
-
3
-
5914
Description
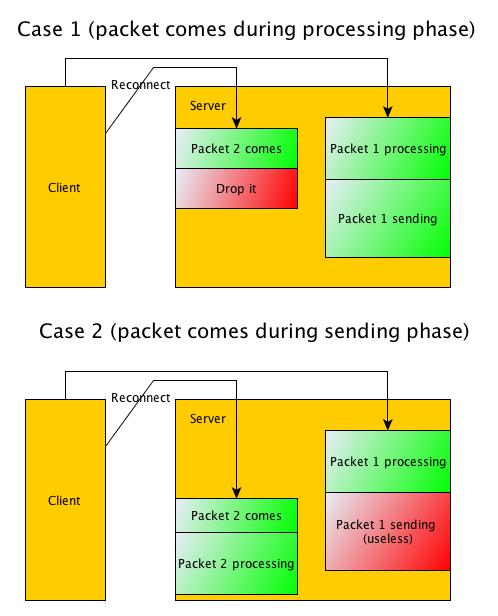
While originally this was a useful workaround, it created a lot of other unintended problems.
This code must be disabled and instead we just should disable handling several duplicate requests at the same time.
Attachments
Issue Links
- duplicates
-
-

- Resolved
-
- is related to
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Closed
-
- Trackbacks
-
![[Confluence: Engineering]](/images/icons/generic_link_16.png "[Confluence: Engineering]") Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA
Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA