Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Lustre 2.1.0, Lustre 2.2.0, Lustre 2.4.0, Lustre 1.8.6
-
3
-
5914
Description
While originally this was a useful workaround, it created a lot of other unintended problems.
This code must be disabled and instead we just should disable handling several duplicate requests at the same time.
Attachments
Issue Links
- duplicates
-
-

- Resolved
-
- is related to
-
-

- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Closed
-
- Trackbacks
-
![[Confluence: Engineering]](/images/icons/generic_link_16.png "[Confluence: Engineering]") Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA
Lustre 1.8.x known issues tracker
While testing against Lustre b18 branch, we would hit known bugs which were already reported in Lustre Bugzilla https://bugzilla.lustre.org/. In order to move away from relying on Bugzilla, we would create a JIRA
Activity
Mike
Could you please clarify what LLNL would need to port in order to use this fix on b2_4?
Thanks
Peter
I think this patch introduced a timeout in conf-sanity (LU-4349), so that needs to be addressed before this patch is introduced into the 2.4 release.
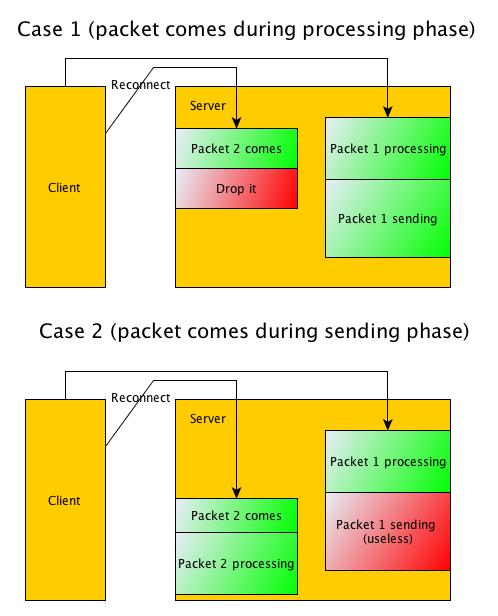
The behavior is almost the same as before for bulks. Currently all pending bulks are aborted if new reconnect arrived from client and reconnect is refused with -EBUSY until there will be no more active requests, this is how it is handled before patch. With this patch we accept reconnect even if there are active requests and all bulks from last connection are aborted. Basically it is the same behavior as before, but now the connection count is checked instead of specific flag.
Client will resend aborted bulks, yes. Also the client is able to reconnect always, but resent bulk may stuck on original bulk until it is aborted.
Unfortunately, no, we won't be able to find out it it helps for some time. We are doing a major upgrade to Lustre 2.4 over the next 2-3 weeks on the SCF machines, but this patch missed the window for inclusion in that distribution. We will have to work it into the pipeline for the next upgrade.
Can you explain a little more about what the patch will do? I see "Bulk requests are aborted upon reconnection by comparing connection count of request and export." in the patch comment. What happens when the bulk requests are aborted? Will the client transparently resend them?
Also, what happens if there is more than one rpc outstanding? Is the client able to reconnect in that case?
Patch was updated again and I hope it addresses all cases including bulk requests. It doesn't change protocol now. Cris, I expect this patch will be landed soon to the master, can you try it and see how it helps?
Patch is refreshed, now it handles all request including bulk. That requires protocol changes and works only with new clients, old clients will be handled as before - returning -EBUSY on connect request if there is another request in processing
This is still a support priority, but we need to finalize the fix before we consider it for inclusion in a release
patch was refreshed http://review.whamcloud.com/#/c/4960/. I doesn't handle bulk request for now, this will be solved in the following patch.
This patch doesn't work properly with bulk resends because bulks use new XID always, even for RESENT case. Therefore we cannot match original request that might be processed on server at the same time. It is not clear how to solve this in simple way in context of this patch, looks like patch should be reworked and will be more complex, e.g. we might need to change protocol and store original XID in bulk along with new one.
Btw, the comment about bulk XID and replated code:
int ptlrpc_register_bulk(struct ptlrpc_request *req) { ... /* An XID is only used for a single request from the client. * For retried bulk transfers, a new XID will be allocated in * in ptlrpc_check_set() if it needs to be resent, so it is not * using the same RDMA match bits after an error. */ ... } and void ptlrpc_resend_req(struct ptlrpc_request *req) { DEBUG_REQ(D_HA, req, "going to resend"); lustre_msg_set_handle(req->rq_reqmsg, &(struct lustre_handle){ 0 }); req->rq_status = -EAGAIN; spin_lock(&req->rq_lock); req->rq_resend = 1; req->rq_net_err = 0; req->rq_timedout = 0; if (req->rq_bulk) { __u64 old_xid = req->rq_xid; /* ensure previous bulk fails */ req->rq_xid = ptlrpc_next_xid(); CDEBUG(D_HA, "resend bulk old x"LPU64" new x"LPU64"\n", old_xid, req->rq_xid); } ptlrpc_client_wake_req(req); spin_unlock(&req->rq_lock); }
Peter, the
LU-793andLU-4349are needed.