-
Improvement
-
Resolution: Fixed
-
 Minor
Minor
-
None
-
None
-
9223372036854775807
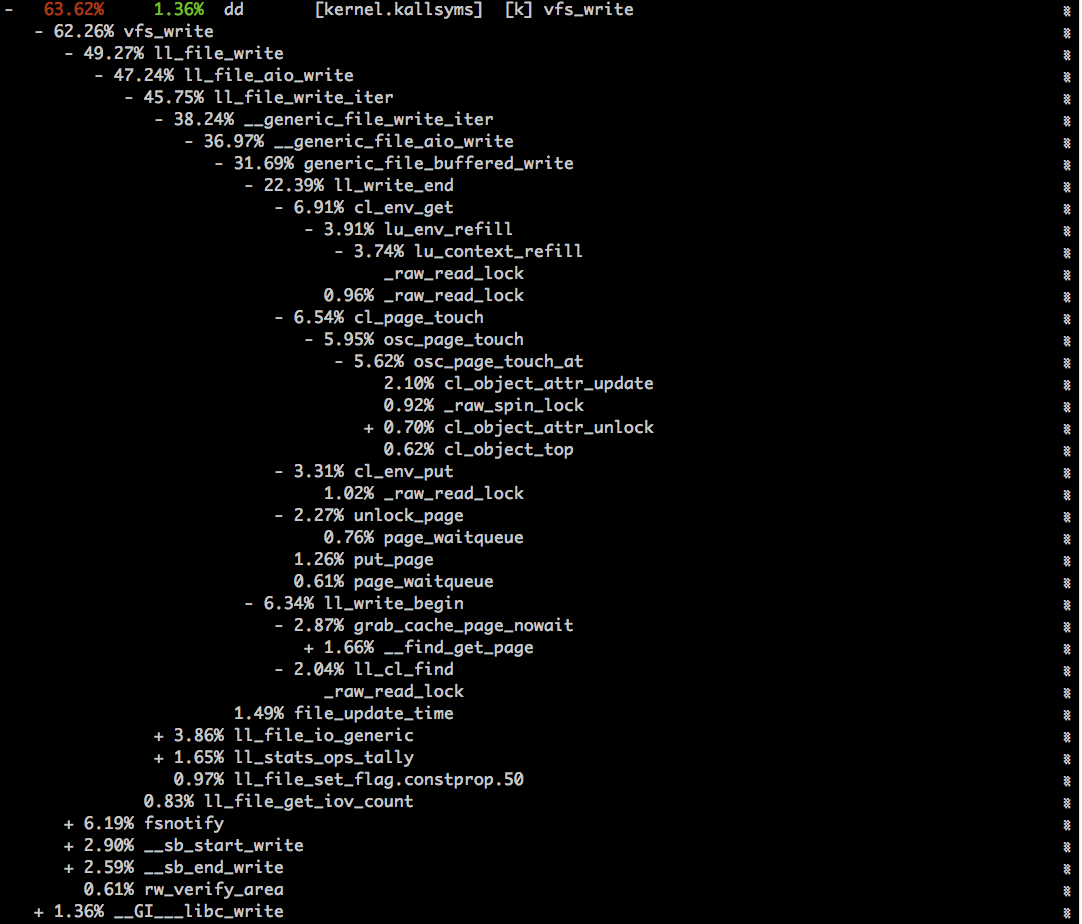
This task is going to address the problem of poor small IO write performance in Lustre.
We only talk about cached I/O here because LU-4198 has a decent solution to improve AIO + DIO for small I/O.
Also for the workload of small I/O, it assumes the pattern of I/O is highly predicated. In another word, it won't help the workload of small random I/O.
The small I/O doesn't have to be page aligned.
(detailed HLD in pogress)