Details
-
Improvement
-
Resolution: Fixed
-
 Minor
Minor
-
None
-
9223372036854775807
Description
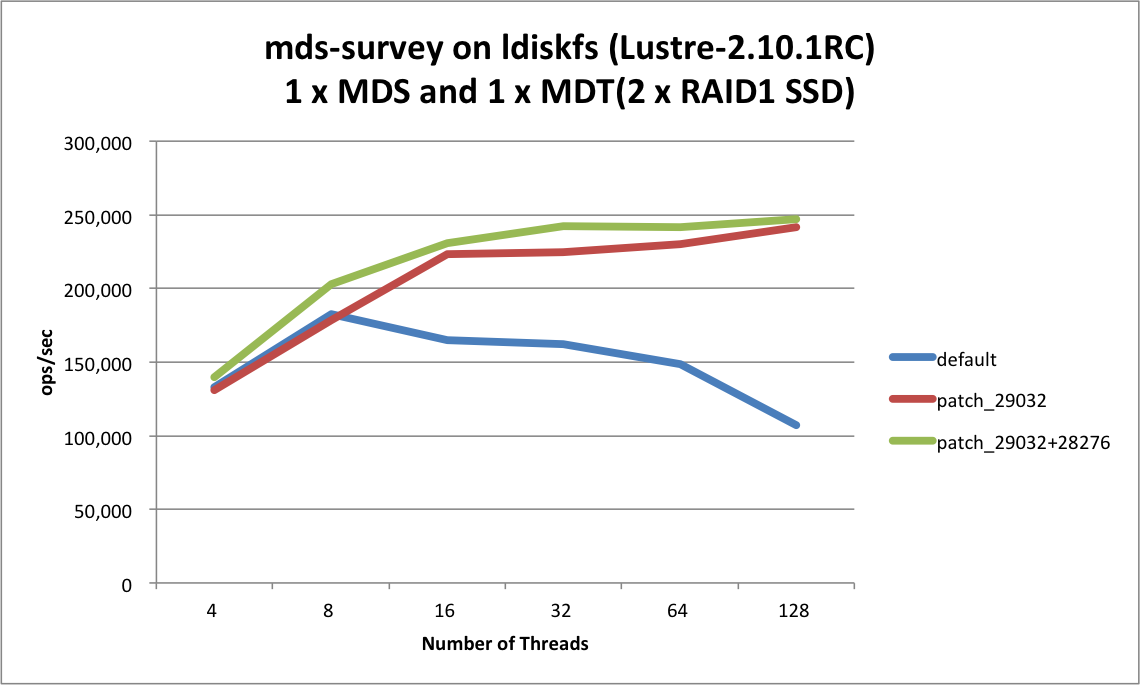
In general, there are some metadata performance regression with/without quota.
Now, Project quota introduced, it's time to measure metadata and improve metadata performance when quota is enabled.
Also, it seems upstream kernel has some performance optimizations for ext4 when quota enabled. It might be possible to get those optimization for Lustre.