-
New Feature
-
Resolution: Unresolved
-
 Minor
Minor
-
None
-
None
-
None
-
9223372036854775807
Currently, there are several ways to control the striping of files:
1) Default striping inherited from parent directory
2) OST pool based striping inherited from parent directory
3) Specific striping on a user defined set of OSTs through creating with open
flag O_LOV_DELAY_CREATE and then ioctl(LL_IOC_LOV_SETSTRIPE)
The default or OST pool based striping tries to ensure that space is evenly
used by OSTs and OSSs, thus the algorithm allocates OST objects according to
the free space on the OSTs. The algorithm is written in kernel space codes,
which means the administrators barely have any way to change the striping
policy even if they realize there are a better policies than the current one.
The application can surely control the striping of the newly created files by
using open flag O_LOV_DELAY_CREATE and ioctl(LL_IOC_LOV_SETSTRIPE). However,
changing the application codes is usually a hard mission and it never happens
for most applications. And individual applications would not have either enough
information or capability to enforce a specific system-wide policy of striping.
That is the reason why we implemented a entirely new striping framework with
the name of RTDS(Real-Time Dynamic Striping).
RTDS controls the striping based on the allocating weights of the OSTs. When
allocating an OST object, RTDS randomly choose an OST. The possibility of
choosing an given OST is proportional to the OST's weight. An allocating weight
is an unsigned number which can be configured by a user space daemon. If a OST
has a weight of zero, then none of the newly created objects will be allocated
on the OST. Let's assume that there are N OSTs, and the OST i has a weight of
W[i], the possibility of allocating a object on the OST i is P[i], then:
S[i] = W[0] + W[1] + W[2] + ... + W[i]
P[i] = W[i] / S[N - 1]
1 = P[0] + P[1] + P[2] + ... + P[N - 1]
In the implementation of RTDS, an RTDS tree is used to choose the OST according
to the weights. An RTDS tree is a binary tree that has following features:
1) The leaves of the RTDS tree is a array with the value of wights, i.e. W[i];
2) The value of the none-leaf node is S[x]. x is the biggest index of the leave in its left
sub-tree.
3) The left sub-tree of a none-leaf node should always be complete binary tree.
Because of rule 3), if a RTDS tree has N leaves (N > 2), then its left sub-tree
has round_down_power_of_2(N) leaves. round_down_power_of_2(N) is the biggest
number that is smaller than N and is the power of 2.
Following is the allocation tree for 8 OSTs.
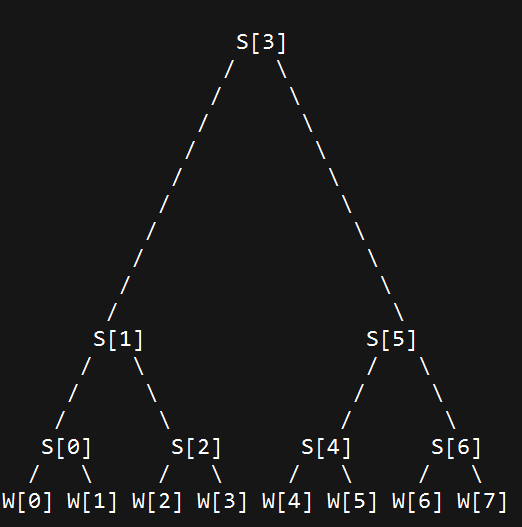
When choosing an OST to allocate the object, the RTDS policy first generate
a random value between 0 and S[N - 1] - 1. The value will be used to travel
RTDS tree from the root node. If the random value is smaller than a non-leaf
node's value, then the left sub-tree should be choosen, otherwise the right
sub-tree should be choosen. By using the policy, the objects can be allocated
on OSTs randomly, and at the same time the striping ratios between OSTs are
kept.
Currently, only a single RTDS tree is used for default striping. In the future,
multiple RTDS trees will be supported. One RTDS tree is used for each striping
policy. And matching rules will be used to determine which one of the striping
policies should be applied for a given file. The matching rules includes a
series of rules based on the attributes of the newly created file or the
process that is creating the file, e.g. UID, GID, NID, Project ID, Job ID etc.
By using the RTDS, administrator will be able to fully control the striping
policies. Interfaces of configuring the RTDS weights and matching rules will
enable a of new use cases, including:
1) When new OSTs are added into the file system, the administrator might want
to quickly balance the space usages between old OSTs and empty OSTs. Thus, the
striping policy should allocate more new objects on new OSTs than old OSTs.
The administrator can configure higher weights for empty OSTs, which will
eventually cause more balanced space usage on all OSTs.
2) If the file system have of OSTs, SSD based OSTs and HD based OSTs, then a
special kind of striping policy might be necessary to control the usage of
the high speed OSTs. The administrator might only want to let a specific job
to use SSD based OSTs. And also, by combining project quota with RTDS, the
administrator can fully control and limit the space usage of the SSD based
OSTs.
3) When OSTs are doing RAID rebuilding, there might be some performance
degradation. That is one of the cases that OSTs has different peformances
which are dynamically changing from time to time. With RTDS, the adminsitrator
could changing the striping weights according to the current available
bandwiths. Since RTDS is a highly configurable, the administrator can implement
many kinds of policies in user space, e.g. policy based on free bandwidth,
policy based on free space, etc.
4) In order to provide better QoS guarantees, the administrator might implement
policy to reserve the bandwidths of a certain part of OSTs. For example, some
OSTs could be excluded from the striping policy and reserved for a certain job.
Together with TBF NRS policy, a series of QoS solutions could be implemented
based on RTDS.
Currently, RTDS are only implemented for file striping. However, this general
framework could be re-used for directory striping too.
If RTDS works well, codes of OST pool can be removed completely since RTDS
should be able to satisfy all the requirements that OST pool can address. Given
the fact that only a few people are using OST pool (according to a simple
survey that I did on LUG), replacing OST pool with RTDS might not be a bad
idea.
