-
Bug
-
Resolution: Unresolved
-
 Critical
Critical
-
None
-
Lustre 2.12.8
-
TOSS 3.7-19 based
RHEL kernel 3.10.0-1160.59.1
lustre 2.12.8_6.llnl
-
3
-
9223372036854775807
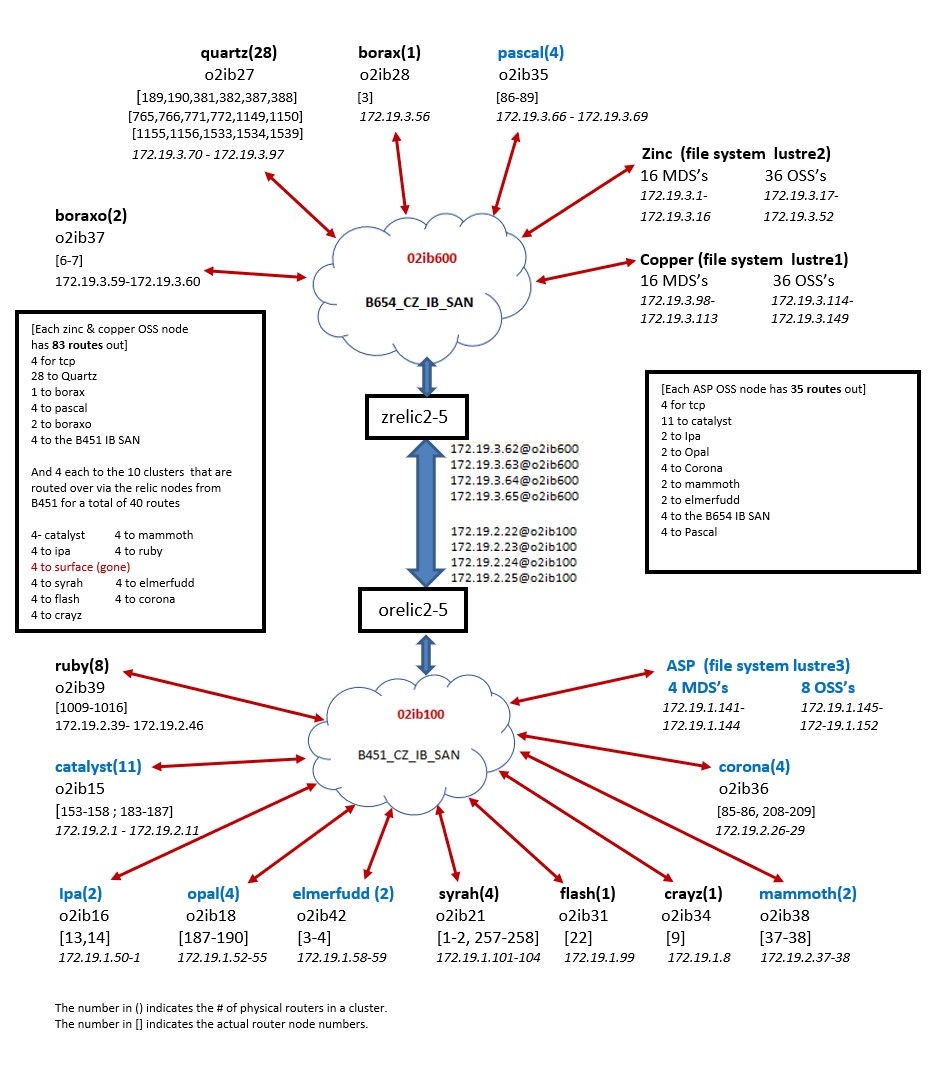
We are having significant lnet issues that have caused us to disable lustre on one of our compute clusters (catalyst). We've had to turn off all of the router nodes in that cluster.
When the routers for catalyst are on we see lots of errors and have connectivity problems on multiple clusters.
This ticket may be useful to explain our lnet setup. https://jira.whamcloud.com/browse/LU-15234
UPDATE: The initial issue have been resolved and our clusters and file systems are working and we don't have to turn off clusters and/or routers anymore. This ticket is now focused on the LNetMDUnlink() containing stack trace as a possible root cause. The OS update and underlying network issues we had seem to have been confounders.
Related to https://jira.whamcloud.com/browse/LU-11895