Details
-
Bug
-
Resolution: Unresolved
-
 Critical
Critical
-
None
-
Lustre 2.12.8
-
TOSS 3.7-19 based
RHEL kernel 3.10.0-1160.59.1
lustre 2.12.8_6.llnl
-
3
-
9223372036854775807
Description
We are having significant lnet issues that have caused us to disable lustre on one of our compute clusters (catalyst). We've had to turn off all of the router nodes in that cluster.
When the routers for catalyst are on we see lots of errors and have connectivity problems on multiple clusters.
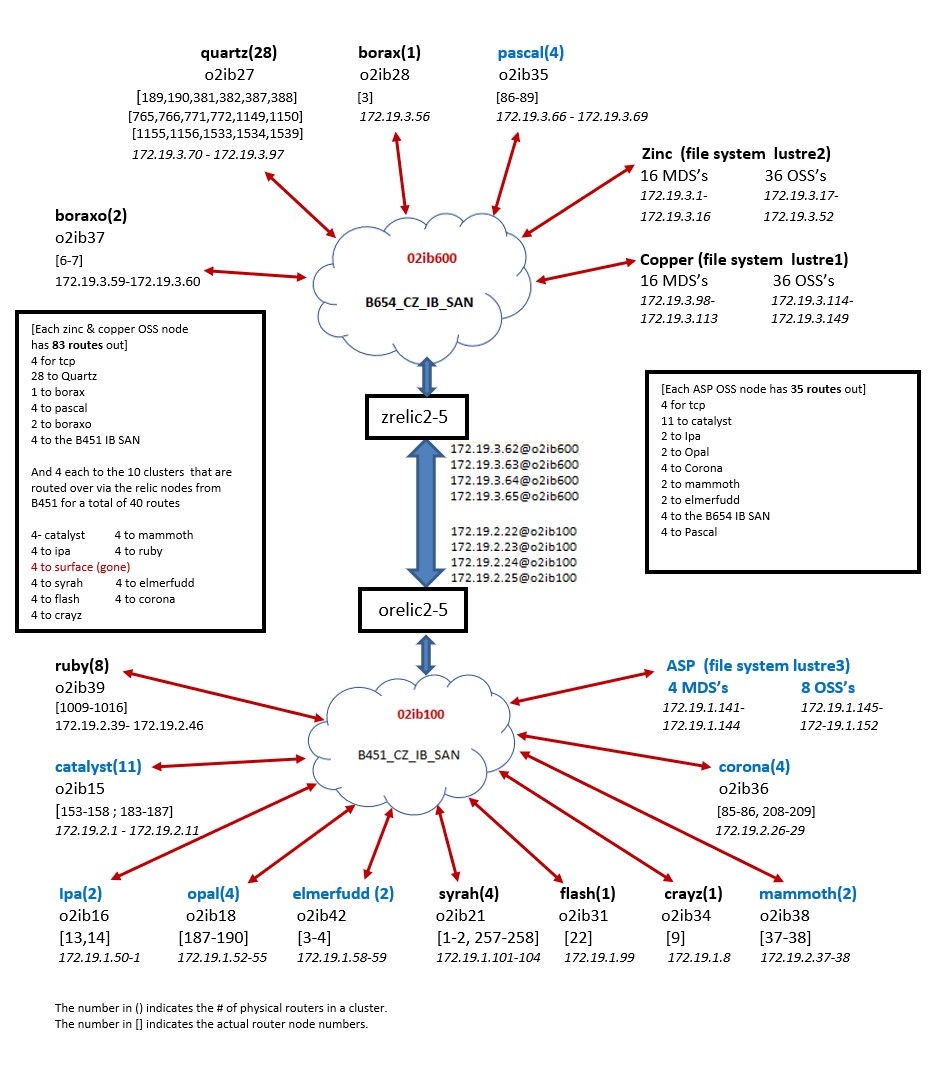
This ticket may be useful to explain our lnet setup. https://jira.whamcloud.com/browse/LU-15234
UPDATE: The initial issue have been resolved and our clusters and file systems are working and we don't have to turn off clusters and/or routers anymore. This ticket is now focused on the LNetMDUnlink() containing stack trace as a possible root cause. The OS update and underlying network issues we had seem to have been confounders.
Related to https://jira.whamcloud.com/browse/LU-11895
Attachments
Activity
I've uploaded the console logs for a node that crashed during the call on 2022-04-22, pascal128,
console.pascal128, pascal128-vmcore-dmesg.txt
The migration jobs are now being run on a different cluster, pascal.
pascal is in the same building, B654, as the source and destination of the migrations (zinc to boa).
We're still having issues with dropped messages and hangs and timeouts while the migrations are running. However, some migration jobs have been able to complete.
The machines in B451 and the relic routers look good now that they're not involved in the migration.
Cameron started running tests before I could.
He ran an ior test with 1m block sizes and had no issues.
He ran this ior command with no issues:
ior -a POSIX -i 2 -b 32G -t 32k -F -C -e -z -o /p/asplustre2/harr1/OST0000/2204201032 -v -v -wWr -g -d 15
We had a configuration change made to the 2 infiniband networks, B654_CZ_IB_SAN and B451_CZ_IB_SAN, which turned on hardware proxy mode. This was because hardware proxy mode had helped with another issue at our site on a different network.
After hardware proxy mode was turned on, Cameron ran his migration jobs again. They caused issues, including the same errors we've seen previously on the relic routers and timeouts and disconnect for other clusters on the network.
However, there are currently 3 migration jobs running our things look ok, and a few have been able to complete today.
That might be the case, but it's hard to tell due to how Cameron's migration script works.
Me:
also, does your migration script tell you what phase of dsync you're in? That is, is it possible to see what phase you're in when things start going bad? Serguei seems to think that things were fine during the walk of zinc (FS "A"), which is kinda how it looked to me too yesterday.
Cameron:
That's not quite how the jobs work. The script first looks for the heaviest users and prioritizes them at the top of the user list, then goes through the user list and submits a new job for each user or group directory at the root of the file system. So there's always a mix of jobs doing pure syncing and some doing walking
You are correct that the tool we're using, dsync from Mpifileutils, scans (or walks) the source and destination before making changes to the destination.
We have done IO testing on boa (FS "B"), although a lot of it was testing hardware and zfs performance, not lustre. However we've done lustre testing on it as well.
I ran some IOR benchmarks on boa about 2 months ago after an OS update that changed the lustre version. However my tests used relatively large transfer sizes (2M) and block sizes (2G). I don't have any records of tests using small transfer and block sizes.
We generally use catalyst for such tests and transfers because catalyst has a lot of spare cycles, and we did use it for some (and I believe most) of the initial performance testing on boa.
I'll try some IOR runs with smaller sizes from catalyst.
These messages in orelic logs:
Apr 19 15:22:28 orelic4 kernel: LNetError: 15918:0:(socklnd.c:1681:ksocknal_destroy_conn()) Completing partial receive from 12345-172.16.70.64@tcp[1], ip 172.16.70.64:988, with error, wanted: 224, left: 224, last alive is 0 secs ago
are likely caused by connection getting destroyed while transferring data, but I haven't yet been able to establish why the connection is getting destroyed.
My understanding is that
- there are 2 FS involved and the migration job is first scanning FS "A" and then, after a while, applying changes to FS "B"
- the issue starts happening when FS "B" starts getting accessed
Is is correct? If so, have you tried any other (fio) tests with FS "B" (using same catalyst nodes)?
I've added pfstest-nodes.tar.gz which has the console logs for slurm group pfstest on catalyst. These are the nodes used to perform the migration.
Gian-Carlo,
Would it be possible to provide the dmsg from the compute node(s) used to run the migration job around the time of the issue? It looks like these may be useful after all.
Thanks,
Serguei.
I've added the lustre logs from today's call as call-2022-4-19.tar.gz
boa isn't on the diagram yet, but it's in building 654, the same as zinc.
The fix we had during the call (which was keeping catalyst154 off) didn't last . We're currently having issues even with all the catalyst routers off. It seems like we have underlying network issues on another compute cluster, quartz.
As for the stack trace from LU-14282, Brian Behlendorf noticed that and we made sure that net was turned off. It's usually off on our systems.
I've uploaded some logs for the relic clusters, including from the infiniband subnet manager. If you look at the network digram, the subnet managers for the 2 SANs are on orelic1 and zrelic1.
Would you be able to do another call today?
The stack traces from the logs look very similar those from https://jira.whamcloud.com/browse/LU-11100 and several duplicate linked bugs.
There was a comment in
LU-11100asking for additional information about who was holding the lock. According to the NMI watchdog the holder appears to be executing the list_for_each_entry loop in LNetMDUnlink() -> lnet_handle2md() -> lnet_res_lh_lookup(). We observed this in the stack traces from multiple clients which hit the issue.struct lnet_libhandle * lnet_res_lh_lookup(struct lnet_res_container *rec, __u64 cookie) { ... list_for_each_entry(lh, head, lh_hash_chain) { if (lh->lh_cookie == cookie) return lh; } return NULL; }