-
Improvement
-
Resolution: Unresolved
-
 Major
Major
-
None
-
Lustre 2.8.0
-
3
-
9223372036854775807
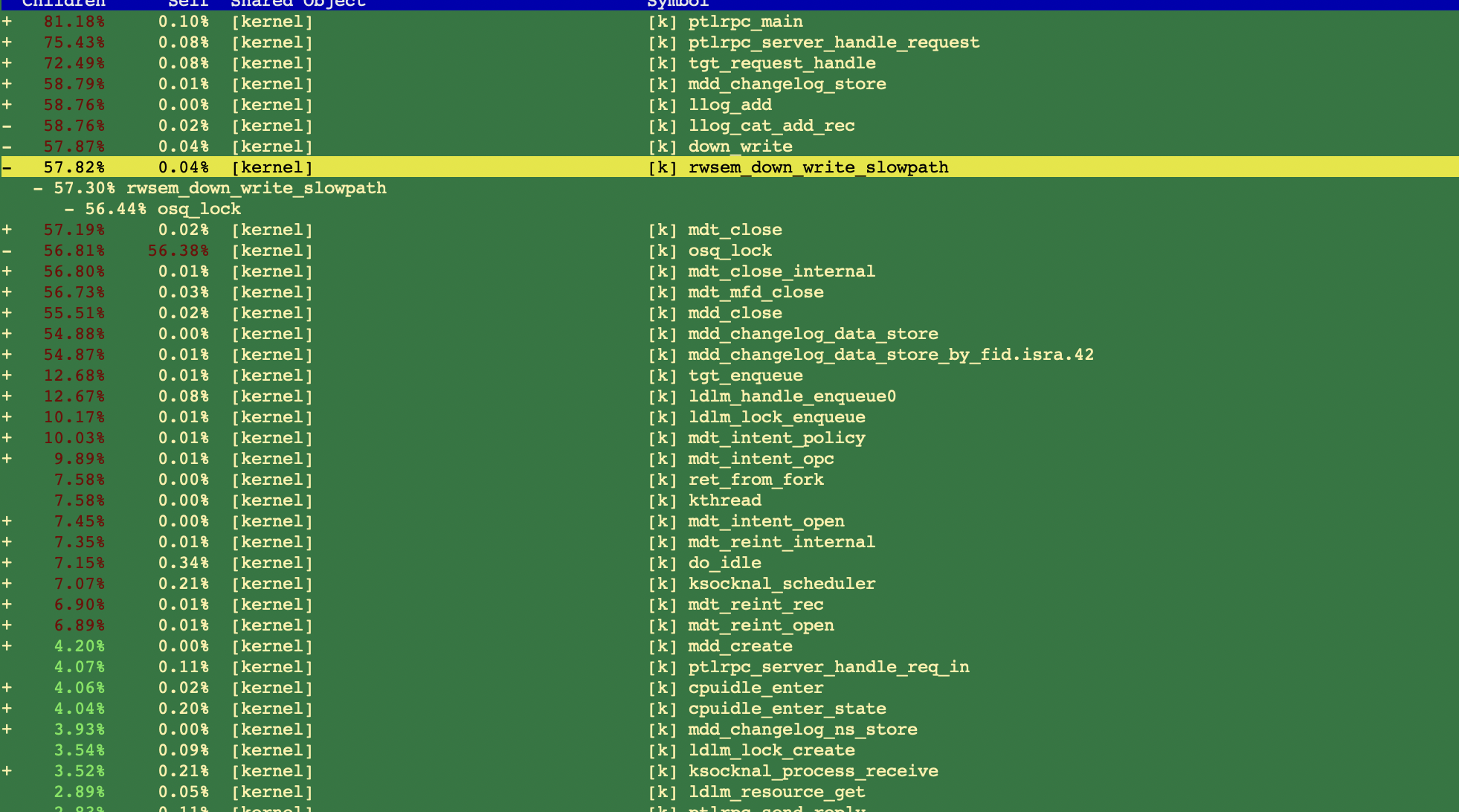
Current llog bitmap header and records structure is not very nice for recording update llog of DNE, especially for remote update log.
In DNE, update records will be written by top_trans_start()->sub_updates_write()->llog_osd_write_rec()->osp_md_write(), where the write buffer (header bitmap + record) will be packed into the RPC buffer, then it will be sent during transaction stop.
To avoid bitmap being over-written, these RPC needs be serialized and also sent with certain order.
But there are still other problems. In llog_osd_write_rec(), it will packed header information (bitmap, lgh_index, offset etc) into the RPC buffer, but the RPC will not be sent until the transaction stop. Then these information might be invalid when the RPC is being sent, especially if the previous llog update RPC fails. And these RPCs are executed on the remote MDT, it will definitly make update llog corrupted.
There are a few options to fix the problem
1. Once any llog update RPC fails, then all of the following RPC in the sending list fails, and OSP will update the header and the new RPC will be packed with updated header. This is 2.8 approach in patch http://review.whamcloud.com/16969 "LU-7039 llog: update llog header and size", and it is easy to implement but not very nice.
2. Add special llog API in OSP->OUT interface, so the OUT can handle these add llog update records independently, instead of only using dumb write API driven by llog_osd_write_rec(). For example we can add such llog updates inside the RPC,
1. append the record.
2. get the llog index.
3. update record with the index.
4. set the bitmap by index.
3.Using other format for update format.
Any thoughts?
- is related to
-
LU-8753 Recovery already passed deadline with DNE
-

- Resolved
-
-
LU-12310 MDT Device-level Replication/Mirroring
-

- Open
-
-
 LU-17821
LMR1c: Improve DNE Distributed Transaction Performance
LU-17821
LMR1c: Improve DNE Distributed Transaction Performance
-
- Open
-
-
-
- Closed
-
- is related to
-
-

- Resolved
-
-
-
- Open
-
-
-
- Open
-
-
-
- Closed
-
- mentioned in
-
Page Loading...
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-