-
Improvement
-
Resolution: Duplicate
-
 Minor
Minor
-
None
-
Lustre 2.10.0
-
9223372036854775807
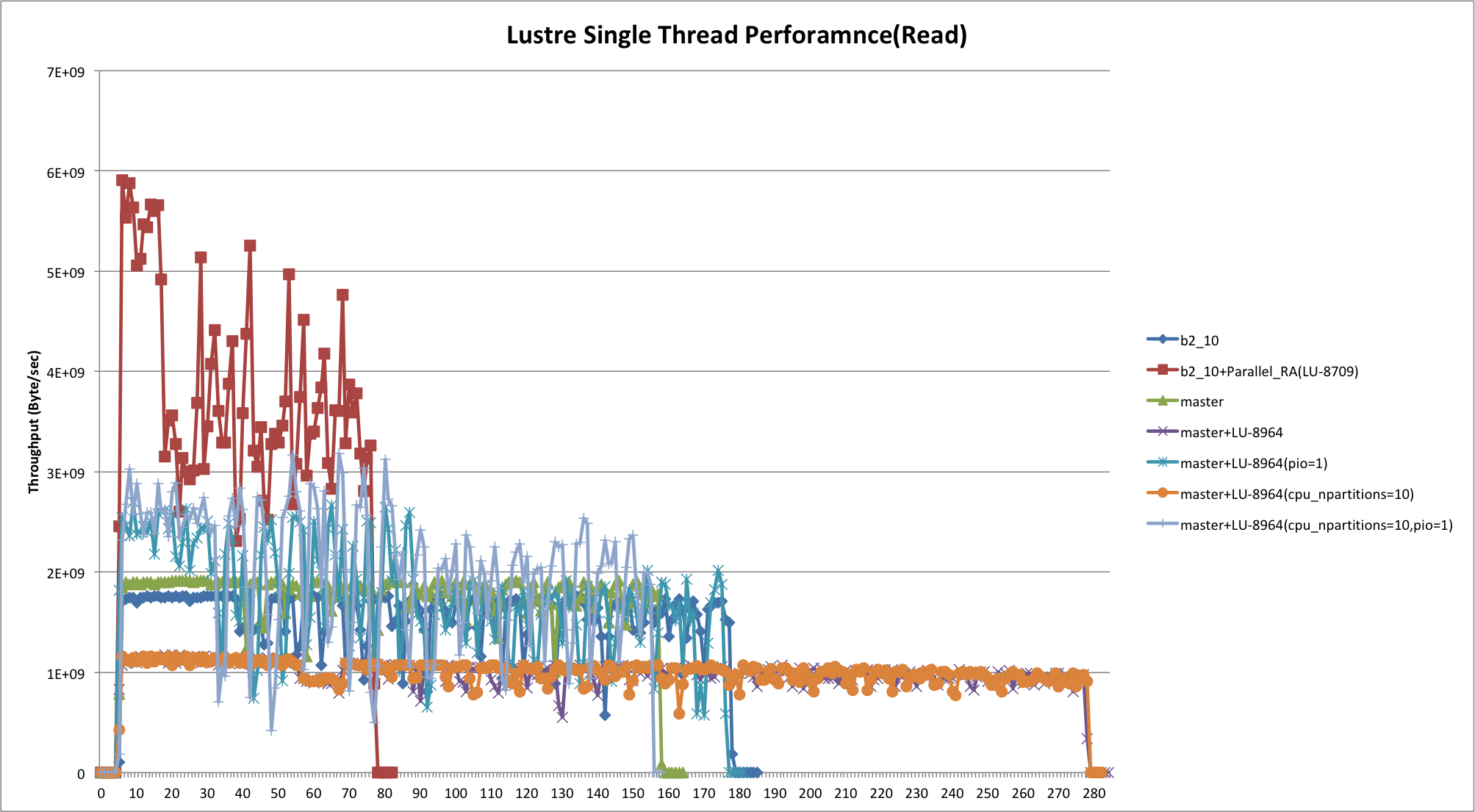
Tracker for parallel async readahead improvement from DDN, as described in http://www.eofs.eu/_media/events/lad16/19_parallel_readahead_framework_li_xi.pdf
Note that it would be very desirable in the single thread case if the copy_to_user was also handled in parallel, as this is a major CPU overhead on many-core systems and if it can be parallelized it may increase the peak read performance.
As for lockahead integration with readahead, I agree that this is possible to do this, but it is only useful if the client doesn't get full-file extent locks. It would also be interesting if the write code detected sequential or strided writes and did lockahead at write time.
- is blocked by
-
-
- Resolved
-
- is duplicated by
-
-

- Resolved
-
- is related to
-
LU-8413 sanity test_101f fails with 'misses too much pages!'
-
- Resolved
-
-
LU-8964 use parallel I/O to improve performance on machines with slow single thread performance
-
- Resolved
-
-
-
- Open
-
-
-
- Resolved
-