-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
Lustre 2.4.0
-
Tested on 2.3.64 and 1.8.9 clients with 4 OSS x 3 - 32 GB OST ramdisks
-
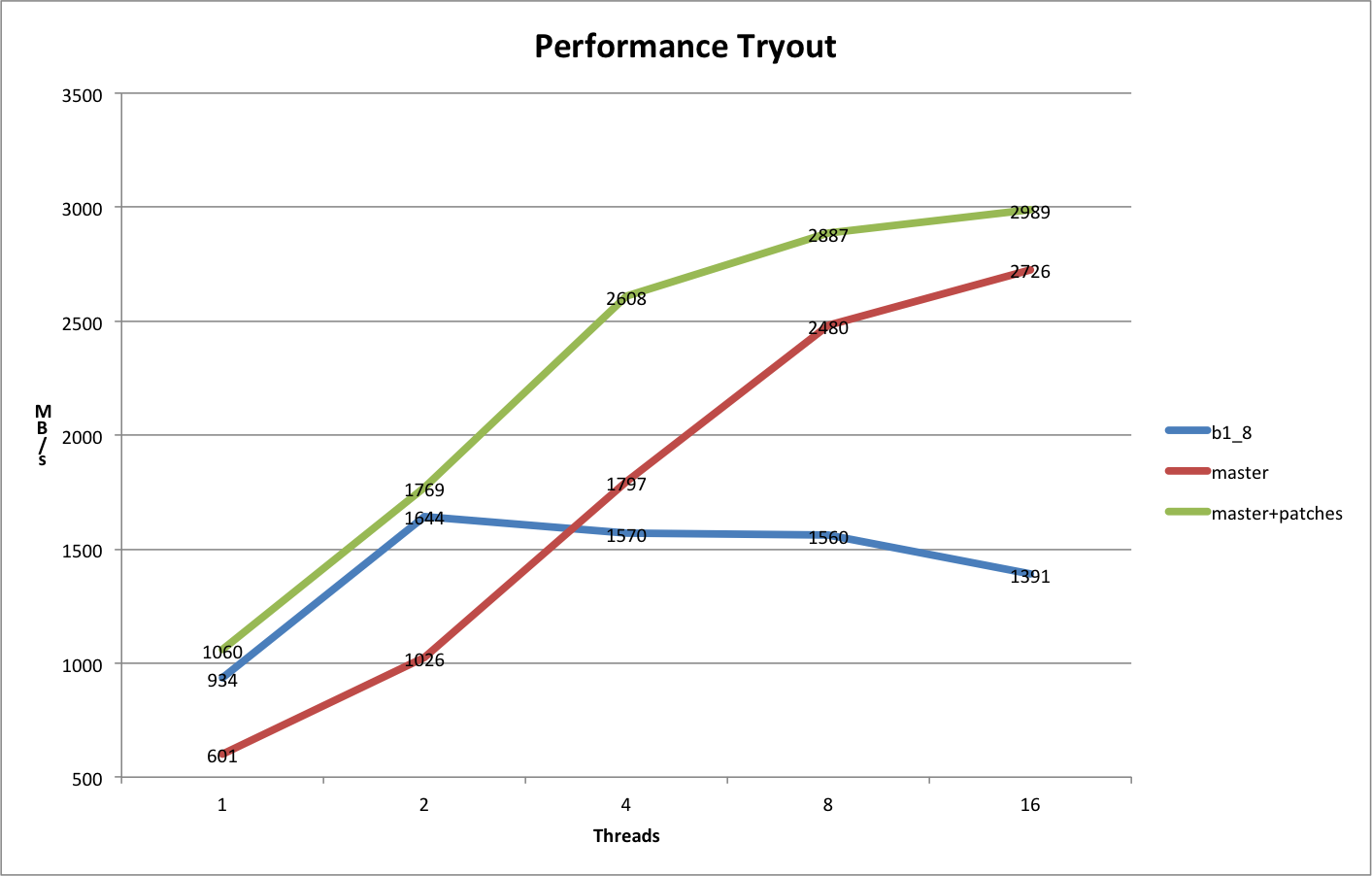
3
-
8259
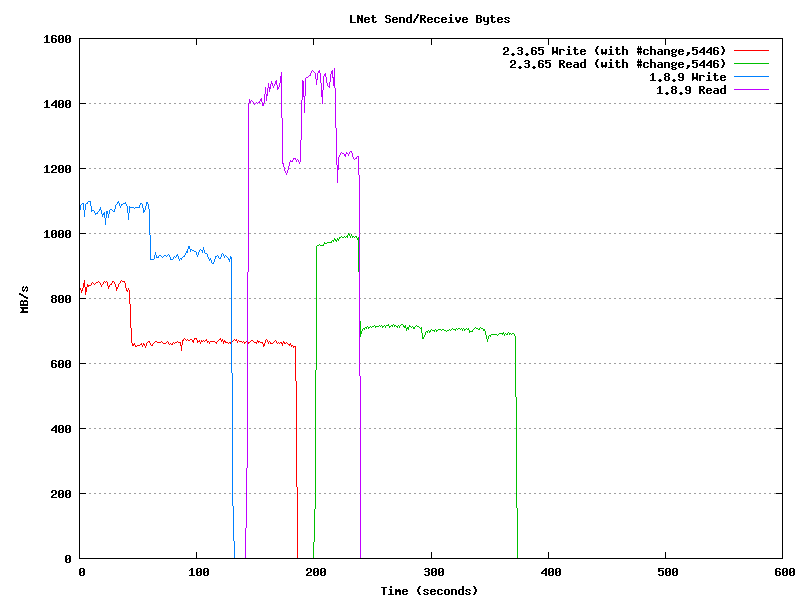
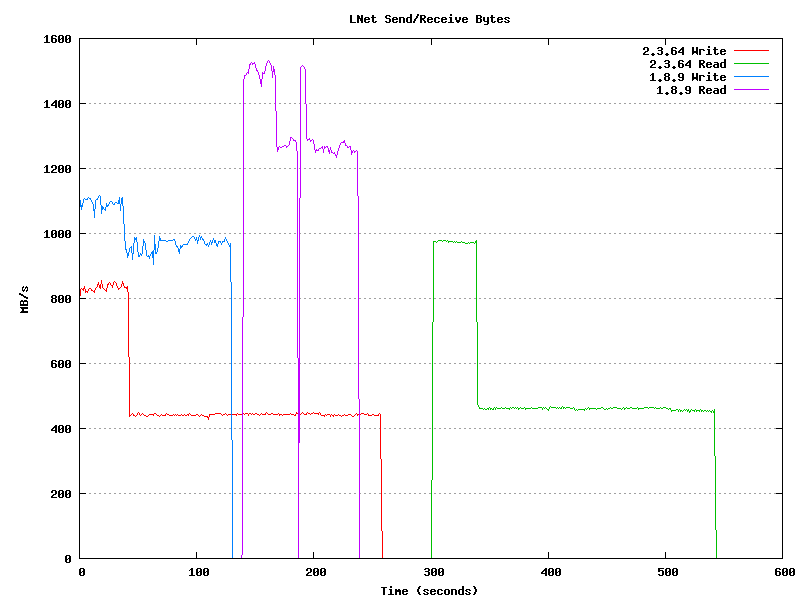
Single thread/process throughput on tag 2.3.64 is degraded from 1.8.9 and significantly degraded when the client hits its caching limit (llite.*.max_cached_mb). Attached graph shows lnet stats sampled every second for a single dd writing 2 - 64 GB files followed by a dropping cache and reading the same two files. The tests were not done simultaenously but the graph has them starting from the same point. It also takes a significant amount of time to drop the cache on 2.3.64.
Lustre 2.3.64
Write (dd if=/dev/zero of=testfile bs=1M)
68719476736 bytes (69 GB) copied, 110.459 s, 622 MB/s
68719476736 bytes (69 GB) copied, 147.935 s, 465 MB/s
Drop caches (echo 1 > /proc/sys/vm/drop_caches)
real 0m43.075s
Read (dd if=testfile of=/dev/null bs=1M)
68719476736 bytes (69 GB) copied, 99.2963 s, 692 MB/s
68719476736 bytes (69 GB) copied, 142.611 s, 482 MB/s
Lustre 1.8.9
Write (dd if=/dev/zero of=testfile bs=1M)
68719476736 bytes (69 GB) copied, 63.3077 s, 1.1 GB/s
68719476736 bytes (69 GB) copied, 67.4487 s, 1.0 GB/s
Drop caches (echo 1 > /proc/sys/vm/drop_caches)
real 0m9.189s
Read (dd if=testfile of=/dev/null bs=1M)
68719476736 bytes (69 GB) copied, 46.4591 s, 1.5 GB/s
68719476736 bytes (69 GB) copied, 52.3635 s, 1.3 GB/s

- is related to
-
-

- Open
-
-
-

- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Resolved
-
-
LU-2946 vvp_write_{pending|complete} should be inode based
-
- Resolved
-
- is related to
-
-
- Resolved
-
-
-
- Resolved
-