Details
-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
Lustre 2.4.0
-
Tested on 2.3.64 and 1.8.9 clients with 4 OSS x 3 - 32 GB OST ramdisks
-
3
-
8259
Description
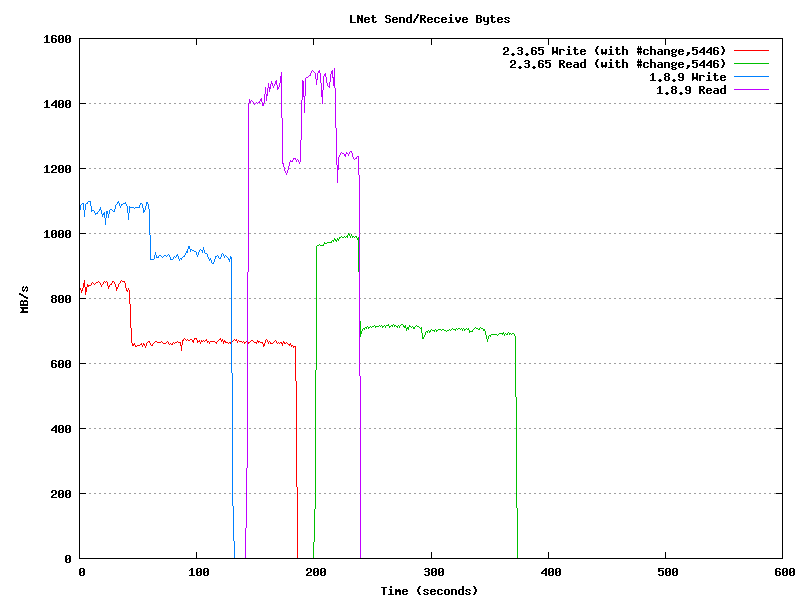
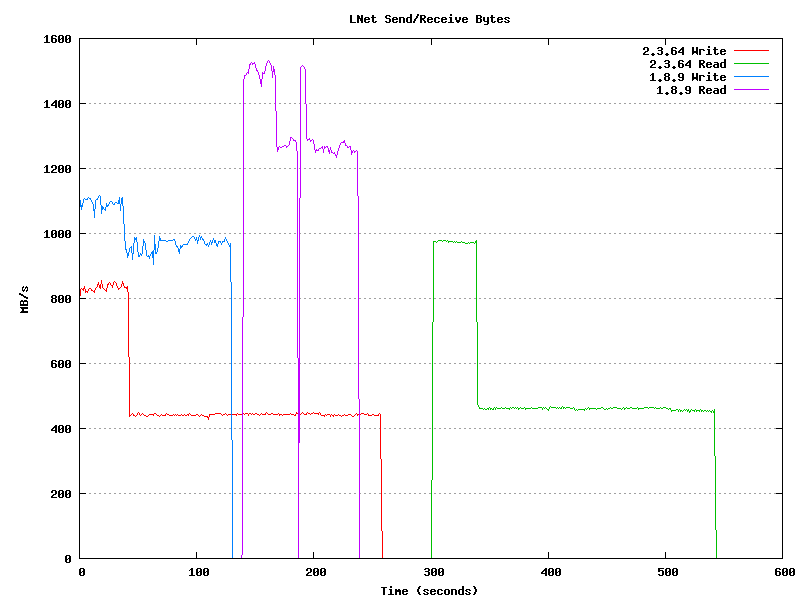
Single thread/process throughput on tag 2.3.64 is degraded from 1.8.9 and significantly degraded when the client hits its caching limit (llite.*.max_cached_mb). Attached graph shows lnet stats sampled every second for a single dd writing 2 - 64 GB files followed by a dropping cache and reading the same two files. The tests were not done simultaenously but the graph has them starting from the same point. It also takes a significant amount of time to drop the cache on 2.3.64.
Lustre 2.3.64
Write (dd if=/dev/zero of=testfile bs=1M)
68719476736 bytes (69 GB) copied, 110.459 s, 622 MB/s
68719476736 bytes (69 GB) copied, 147.935 s, 465 MB/s
Drop caches (echo 1 > /proc/sys/vm/drop_caches)
real 0m43.075s
Read (dd if=testfile of=/dev/null bs=1M)
68719476736 bytes (69 GB) copied, 99.2963 s, 692 MB/s
68719476736 bytes (69 GB) copied, 142.611 s, 482 MB/s
Lustre 1.8.9
Write (dd if=/dev/zero of=testfile bs=1M)
68719476736 bytes (69 GB) copied, 63.3077 s, 1.1 GB/s
68719476736 bytes (69 GB) copied, 67.4487 s, 1.0 GB/s
Drop caches (echo 1 > /proc/sys/vm/drop_caches)
real 0m9.189s
Read (dd if=testfile of=/dev/null bs=1M)
68719476736 bytes (69 GB) copied, 46.4591 s, 1.5 GB/s
68719476736 bytes (69 GB) copied, 52.3635 s, 1.3 GB/s
Attachments

Issue Links
- is related to
-
-

- Open
-
-
-

- Resolved
-
-
-
- Resolved
-
-
-

- Resolved
-
-
-
- Resolved
-
-
LU-2946 vvp_write_{pending|complete} should be inode based
-
- Resolved
-
- is related to
-
-
- Resolved
-
-
-
- Resolved
-
Activity
Hi Pichon,
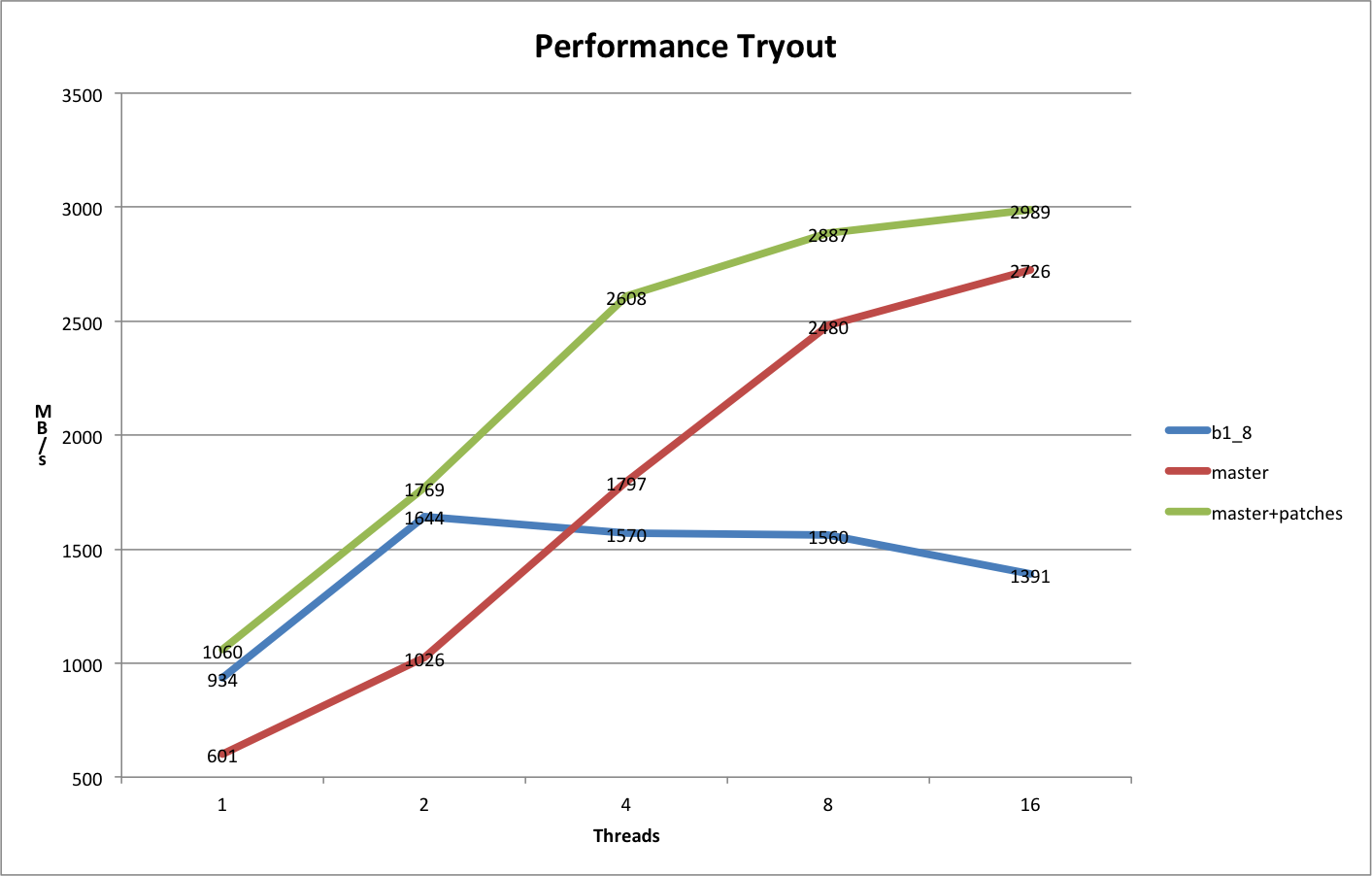
Now that you're asking, I assume the performance number didn't reach your expectation. Therefore I performed the test again with latest master to make sure everything is fine. Please collect statistic data on your node if this is the case, and I will take a look.
I just performed the performance testing again on opensfs nodes with the following hardware configuration:
Client nodes:
[root@c01 lustre]# free
total used free shared buffers cached
Mem: 32870020 26477056 6392964 0 147936 21561448
-/+ buffers/cache: 4767672 28102348
Swap: 16506872 0 16506872
[root@c01 lustre]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 44
Stepping: 2
CPU MHz: 1600.000
BogoMIPS: 4800.10
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 12288K
NUMA node0 CPU(s): 0-7
[root@c01 lustre]# lspci |grep InfiniBand
03:00.0 InfiniBand: Mellanox Technologies MT26428 [ConnectX VPI PCIe 2.0 5GT/s - IB QDR / 10GigE] (rev b0)
So the client node has 32G memory size and 4 Cores with 2 threads on each core. The network is Infiniband with 40Gb/s throughput.
Server node is another client node with patch http://review.whamcloud.com/5164 applied. I used ramdisk as OST because we don't have fast disk array. Jeremy saw real performance improvement on their real disk storage. I disabled writethrough_cache_enable on the OST to avoid consuming too much memory on caching data.
Here is the test result:
[root@c01 lustre]# dd if=/dev/zero of=/mnt/lustre/testfile bs=1M count=40960 40960+0 records in 40960+0 records out 42949672960 bytes (43 GB) copied, 39.5263 s, 1.1 GB/s [root@c01 lustre]# lfs getstripe /mnt/lustre/testfile /mnt/lustre/testfile lmm_stripe_count: 1 lmm_stripe_size: 1048576 lmm_pattern: 1 lmm_layout_gen: 0 lmm_stripe_offset: 0 obdidx objid objid group 0 2 0x2 0
I didn't do any configuration on the client node, even disable checksum. Also the snapshot of `collect -scml':
[root@c01 ~]# collectl -scml waiting for 1 second sample... #<----CPU[HYPER]-----><-----------Memory-----------><--------Lustre Client--------> #cpu sys inter ctxsw Free Buff Cach Inac Slab Map KBRead Reads KBWrite Writes 20 20 5500 26162 18G 144M 10G 9G 1G 45M 0 0 1110016 1084 24 24 5513 23691 17G 144M 11G 10G 1G 45M 0 0 1025024 1001 20 20 5657 26083 15G 144M 12G 11G 2G 45M 0 0 1112064 1086 21 21 5434 25963 14G 144M 13G 12G 2G 45M 0 0 1110016 1084 20 20 5690 26326 13G 144M 14G 13G 2G 45M 0 0 1104896 1079 21 21 5646 26094 11G 144M 15G 14G 2G 45M 0 0 1105920 1080 21 21 5466 24678 10G 144M 16G 15G 3G 45M 0 0 1046528 1022 20 20 5634 25563 9G 144M 17G 16G 3G 45M 0 0 1097728 1072 20 20 5818 26008 8G 144M 18G 17G 3G 45M 0 0 1111040 1085 20 20 5673 26467 6G 144M 20G 18G 3G 45M 0 0 1104896 1079 24 24 6346 25027 6G 144M 20G 19G 4G 45M 0 0 1060864 1036 33 32 7162 21258 6G 144M 20G 19G 4G 45M 0 0 960512 938 28 28 7021 22865 6G 144M 20G 19G 4G 45M 0 0 1042432 1018 28 28 7177 23890 6G 144M 20G 19G 4G 45M 0 0 1039360 1015 28 28 7326 24888 6G 144M 20G 19G 4G 45M 0 0 1090560 1065 28 28 7465 24162 6G 144M 20G 19G 4G 45M 0 0 1029120 1005 31 31 7382 22865 6G 144M 20G 19G 4G 45M 0 0 980992 958 28 28 7263 24392 6G 144M 20G 19G 4G 45M 0 0 1075200 1050 28 28 7278 24312 6G 144M 20G 19G 4G 45M 0 0 1080320 1055 28 28 7252 25150 6G 144M 20G 19G 4G 45M 0 0 1059840 1035 28 28 7241 25082 6G 144M 20G 19G 4G 45M 0 0 1076224 1051 33 32 7343 22373 6G 144M 20G 19G 4G 45M 0 0 966656 944 #<----CPU[HYPER]-----><-----------Memory-----------><--------Lustre Client--------> #cpu sys inter ctxsw Free Buff Cach Inac Slab Map KBRead Reads KBWrite Writes 28 28 7340 24704 6G 144M 20G 19G 4G 45M 0 0 1091584 1066 27 27 7212 24694 6G 144M 20G 19G 4G 45M 0 0 1055744 1031 28 28 7191 24909 6G 144M 20G 19G 4G 45M 0 0 1073152 1048 28 28 7257 25058 6G 144M 20G 19G 4G 45M 0 0 1037312 1013 33 33 7435 22787 6G 144M 20G 19G 4G 45M 0 0 988160 965 28 28 6961 23635 6G 144M 20G 19G 4G 45M 0 0 1044480 1020 27 27 7129 24866 6G 144M 20G 19G 4G 45M 0 0 1045504 1021 28 27 7024 24380 6G 144M 20G 19G 4G 45M 0 0 1053666 1029 28 28 7058 24489 6G 144M 20G 19G 4G 45M 0 0 1041426 1017 33 33 7234 22235 6G 144M 20G 19G 4G 45M 0 0 970752 948 27 27 7127 24555 6G 144M 20G 19G 4G 45M 0 0 1067008 1042 28 28 7189 24215 6G 144M 20G 19G 4G 45M 0 0 1082368 1057 28 28 7201 24734 6G 144M 20G 19G 4G 45M 0 0 1064960 1040 27 27 7046 24564 6G 144M 20G 19G 4G 44M 0 0 1040384 1016 0 0 67 110 6G 144M 20G 19G 4G 44M 0 0 0 0 0 0 63 113 6G 144M 20G 19G 4G 44M 0 0 0 0
Does the dd test include a final fsync of data to storage ?
No I didn't but I don't think this will affect the result because I ran dd with 1M block so the dirty data will be sent out immediately.
Could you provide the details of the configuration where you made your measurements (client node socket, memory size, network interface, max_cached_mb setting, other client tuning, OSS node and OST storage, file striping, io size, RPC size) ?
Does the dd test include a final fsync of data to storage ?
Do you have performance results with a version of Lustre after all the patches have been landed ?
thanks.
the maloo test failed due to an unrelated bug. I will retrigger the test.
John - There are a few components to the review/landing process.
The patch is built automatically by Jenkins, which contributes a +1 if it builds correctly (that's already true for http://review.whamcloud.com/#/c/8523/).
Maloo then runs several sets of tests, currently I think that's three. Once all the sets of tests have passed, Maloo contributes a +1. It looks like two of the three test sets have completed for the patch in question.
Separately, human reviewers contribute code reviews. A positive review gives a +1. The general standard is two +1s before landing a patch.
Then, finally, someone in the gatekeeper role - I believe that's currently Oleg Drokin and Andreas Dilger - approves the patch, which appears as +2. Then the patch is cherry-picked on to master (also by a gatekeeper).
Once the patch has been cherry-picked, it has landed.
This one is almost ready to land. The tests need to complete, then it should be approved and cherry-picked quickly. (Since this ticket is a blocker for 2.6, it'll definitely be in before that release.)
Can anyone tell me about the status of the final patch for this issue? Looks like some recent testing has been successful, but I don't know the other tools well enough to know if the patch is ready to land, or even already landed. Thanks.
Once http://review.whamcloud.com/#/c/8523/ lands this ticket can be closed
No worry, we've already had a patch for percpu cl_env cache. It turns out that the overhead of allocating cl_env is really high, so caching cl_env is necessary, but we just need a smart way to cache them.
Hi Jinshan,
Here are the results of the performance measurements I have done.
Configuration
Client is a node with 2 Ivybridge sockets (24 cores, 2.7GHz), 32GB memory, 1 FDR Infiniband adapter.
OSS is a node with 2 Sandybridge sockets (16 cores, 2.2GHZ), 32GB memory, 1 FDR Infiniband adapter, with 5 OSTs devices from a disk array and 1 OST ramdisk device.
Each disk array OST reaches 900 MiB/s write and 1100 MiB/s read with obdfilter-survey.
Two Lustre versions have been tested: 2.5.57 and 1.8.8-wc1
OSS cache is disabled (writethrough_cache_enable=0 and read_cache_enable=0)
Benchmark
IOR with following options:
api=POSIX
filePerProc=1
blockSize=64G
transferSize=1M
numTasks=1
fsync=1
Server and client system cache is cleared before each write test and read test
Tests are repeated 3 times, average value is computed.
Tests are run as a standard user.
Results
With disk array OSTs, best results are achieved with a stripecount of 3.
The write performance is under the 1GiB/s performance which was my goal. Do you think this is a performance we could achieve ? What tuning would you recommand ? I will provide monitoring data in attachment for one of the lustre 2.5.57 runs.
As an element of comparison, the results with the ram device OST
Various tuning have been tested but give no improvement:
IOR transferSize, llite max_cached_mb, OSS cache enabled.
What makes a significant difference with lustre 2.5.57 is the write performance when test is run as root user, since it reaches 926 MiB/s (+4,5% compared to standard user). Should I open a separate ticket to track this difference ?
Greg.