-
Bug
-
Resolution: Duplicate
-
 Major
Major
-
None
-
Lustre 2.4.2
-
Linux meerkat-mds-10-1.local 2.6.32-358.23.2.el6_lustre.x86_64 #1 SMP Thu Dec 19 19:57:45 PST 2013 x86_64 x86_64 x86_64 GNU/Linux
-
3
-
16369
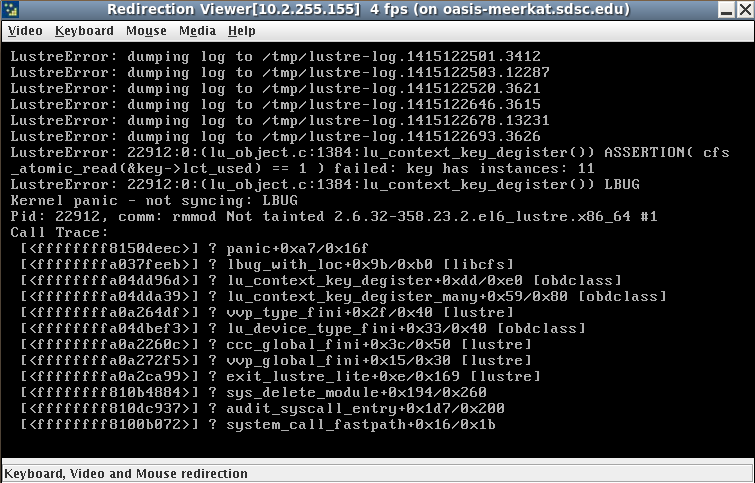
Lustre 2.4.2, MDS reports OOM:
Please see attached logs.